🧐 Find label errors with cleanlab#
In this tutorial we will leverage Rubrix and cleanlab to find, uncover and correct potential label errors. You can do this following 4 basic steps:
💾 load a dataset with potential label errors, here we use the ag_news dataset;
💻 train a model to make predictions for a test set, here we use a lightweight sklearn model;
🧐 use cleanlab via Rubrix and get potential label error candidates in the test set;
🖍 uncover and correct label errors quickly and comfortably with the Rubrix web app;
Introduction#
As shown recently by Curtis G. Northcutt et al. label errors are pervasive even in the most-cited test sets used to benchmark the progress of the field of machine learning. They introduce a new principled framework to “identify label errors, characterize label noise, and learn with noisy labels” called confident learning. It is open-sourced as the cleanlab Python package that supports finding, quantifying, and learning with label errors in data sets.
Rubrix provides built-in support for cleanlab and makes it a breeze to find potential label errors in your dataset. In this tutorial we will try to uncover and correct label errors in the well-known ag_news dataset that is often used to benchmark classification models in NLP.
Setup#
Rubrix, is a free and open-source tool to explore, annotate, and monitor data for NLP projects.
If you are new to Rubrix, check out the ⭐ Github repository.
If you have not installed and launched Rubrix yet, check the Setup and Installation guide.
For this tutorial we also need the third party libraries datasets, sklearn, and cleanlab, which can be installed via pip:
[ ]:
%pip install datasets scikit-learn cleanlab -qqq
Note
If you want to skip the first three sections of this tutorial, and only uncover and correct the label errors in the Rubrix web app, you can load the records directly from the Hugging Face Hub:
import rubrix as rb
from datasets import load_dataset
records_with_label_errors = rb.read_datasets(
load_dataset("rubrix/cleanlab-label_errors", split="train"),
task="TextClassification",
)
1. Load datasets#
We start by downloading the ag_news dataset via the very convenient datasets library.
[ ]:
from datasets import load_dataset
# download data
dataset = load_dataset('ag_news')
We then extract the train and test set, as well as the labels of this classification task. We also shuffle the train set, since by default it is ordered by the classification label.
[ ]:
# get train set and shuffle
ds_train = dataset["train"].shuffle(seed=43)
# get test set
ds_test = dataset["test"]
# get classification labels
labels = ds_train.features["label"].names
2. Train model#
For this tutorial we will use a multinomial Naive Bayes classifier, a lightweight and easy to train sklearn model. However, you can use any model of your choice as long as it includes the probabilities for all labels in its predictions.
The features for our classifier will be simply the token counts of our input text.
[ ]:
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.pipeline import Pipeline
# define our classifier as a pipeline of token counts + naive bayes model
classifier = Pipeline([
('vect', CountVectorizer()),
('clf', MultinomialNB())
])
After defining our classifier, we can fit it with our train set. Since we are using a rather lightweight model, this should not take too long.
[ ]:
# fit the classifier
classifier.fit(
X=ds_train["text"],
y=ds_train["label"]
)
Let us check how our model performs on the test set.
[ ]:
# compute test accuracy
classifier.score(
X=ds_test["text"],
y=ds_test["label"],
)
We should obtain a decent accuracy of 0.90, especially considering the fact that we only used the token counts as input feature.
3. Get label error candidates#
As a first step to get label error candidates in our test set, we have to predict the probabilities for all labels.
[ ]:
# get predicted probabilities for all labels
probabilities = classifier.predict_proba(ds_test["text"])
With the predictions at hand, we create Rubrix records that contain the text input, the prediction of the model, the potential erroneous annotation, and some metadata of your choice.
[ ]:
import rubrix as rb
# create records for the test set
records = [
rb.TextClassificationRecord(
text=data["text"],
prediction=list(zip(labels, prediction)),
annotation=labels[data["label"]],
metadata={"split": "test"}
)
for data, prediction in zip(ds_test, probabilities)
]
We could log these records directly to Rubrix and conveniently inspect them by eye, checking the annotation of each text input. But here we will use a quicker way by leveraging Rubrix’s built-in support for cleanlab. You simply import the find_label_errors function from Rubrix and pass in the list of records. That’s it.
[ ]:
from rubrix.labeling.text_classification import find_label_errors
# get records with potential label errors
records_with_label_error = find_label_errors(records)
The records_with_label_error list contains around 600 candidates for potential label errors, which is more than 8% of our test data.
4. Uncover and correct label errors#
Now let us log those records to the Rubrix web app to conveniently check them by eye, and to quickly correct potential label errors at the same time.
[ ]:
# uncover label errors in the Rubrix web app
rb.log(records_with_label_error, "label_errors")
By default the records in the records_with_label_error list are ordered by their likelihood of containing a label error. They will also contain a metadata called “label_error_candidate” by default, which reflects the order in the list. You can use this field in the Rubrix web app to sort the records as shown in the screenshot below.
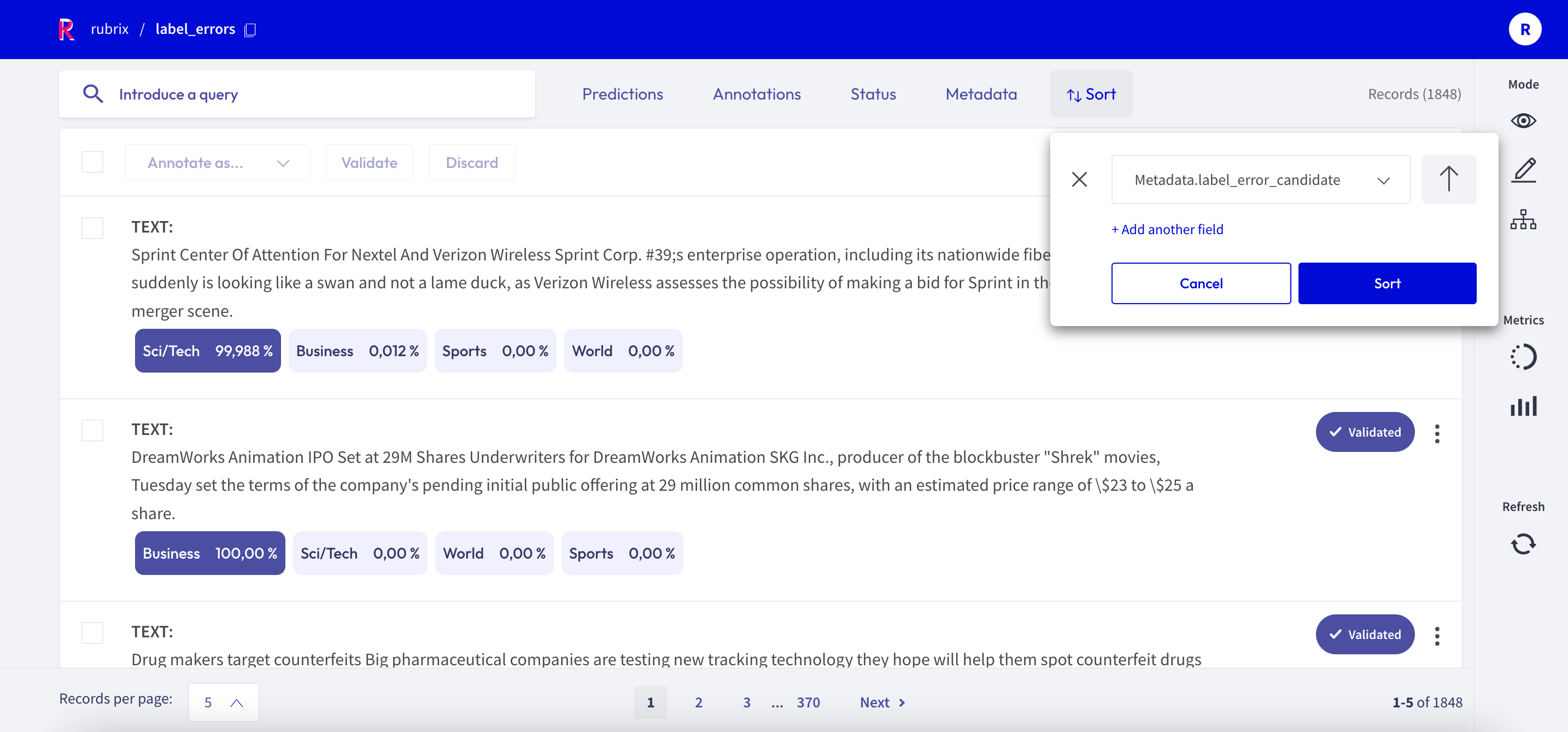
We can confirm that the most likely candidates are indeed clear label errors. Towards the end of the candidate list, the examples get more ambiguous, and it is not immediately obvious if the gold annotations are in fact erroneous.
Summary#
With Rubrix you can quickly and conveniently find label errors in your data. The built-in support for cleanlab, together with the optimized user experience of the Rubrix web app, makes the process a breeze, and allows you to efficiently correct label errors on the fly.
In just a few steps you can quickly check if your test data set is seriously affected by label errors and if your benchmarks are really meaningful in practice. Maybe your less complex models turns out to beat your resource hungry super model, and the deployment process just got a little bit easier 😀.
Although we only used a sklearn model in this tutorial, Rubrix does not care about the model architecture or the framework you are working with. It just cares about the underlying data and allows you to put more humans in the loop of your AI Lifecycle.
Next steps#
⭐ Rubrix Github repo to stay updated.
📚 Rubrix documentation for more guides and tutorials.
🙋♀️ Join the Rubrix community on Slack
Appendix I: Find label errors in your train data using cross-validation#
In order to check your training data for label errors, you can fall back to the cross-validation technique to get out-of-sample predictions. With a classifier from sklearn, cross-validation is really easy and you can do it conveniently in one line of code. Afterwards, the steps of creating Rubrix records, finding label error candidates, and uncovering them are the same as shown in the tutorial above.
[ ]:
from sklearn.model_selection import cross_val_predict
# get predicted probabilities for the whole dataset via cross validation
cv_probs = cross_val_predict(
classifier,
X=ds_train["text"] + ds_test["text"],
y=ds_train["label"] + ds_test["label"],
cv=int(len(ds_train) / len(ds_test)),
method="predict_proba",
n_jobs=-1
)
[ ]:
# create records for the training set
records = [
rb.TextClassificationRecord(
text=data["text"],
prediction=list(zip(labels, prediction)),
annotation=labels[data["label"]],
metadata={"split": "train"}
)
for data, prediction in zip(ds_train, cv_probs)
]
[ ]:
# uncover label errors for the train set in the Rubrix web app
rb.log(find_label_errors(records), "label_errors_in_train")
Here we find around 9400 records with potential label errors, which is also around 8% with respect to the train data.
Appendix II: Log datasets to the Hugging Face Hub#
Here we will show you an example of how you can push a Rubrix dataset (records) to the Hugging Face Hub. In this way you can effectively version any of your Rubrix datasets.
[ ]:
records = rb.load("label_errors")
records.to_datasets().push_to_hub("<name of the dataset on the HF Hub>")