🤯 Few-shot classification with SetFit and a custom dataset#
SetFit is an exciting open-source package for few-shot classification developed by teams at Hugging Face and Intel Labs. You can read all about it on the project repository.
To showcase how powerful is the combination of SetFit and Rubrix:
We manually label 55 examples from the unlabelled split of the imdb dataset,
we train a model in 5 min,
and without using a single example from the original imdb training set, we achieve 0.9 accuracy on the full test set!
Summary#
In this tutorial, you’ll learn to:
Load a unlabelled dataset in Rubrix. We’ll be using the unlabelled split from the
imdbmovie reviews sentiment dataset. This same workflow can be applied to any custom dataset, problem, and language!Manually label a FEW examples using the UI.
Train a SetFit model to get highly competitive results. For this example, with only 55 examples, we get 0.9 accuracy on the test set which is comparable to models fine-tuned on 3K examples. That means similar performance with
50xless examples 🤯.
For reference see the Hugging Face Hub and PapersWithCode leaderboards.
Let’s get started!
Setup Rubrix#
Rubrix is a free and open-source data labeling framework for NLP.
To get started on your local machine, you just need three steps:
Install the library:
[19]:
!pip install rubrix[server]
Install and launch Elasticsearch.
Launch the server and the UI from your terminal or notebook:
python -m rubrix
🎉 If everything went well, you can go to https://localhost:6900 and login using the default user/password: rubrix/1234.
🆘 If you need help you can join our Slack channel to get inmediate support.
Setup SetFit and datasets libraries#
[ ]:
!pip install setfit datasets -qqq
[ ]:
from datasets import load_dataset
from sentence_transformers.losses import CosineSimilarityLoss
from setfit import SetFitModel, SetFitTrainer
import rubrix as rb
Load unlabelled dataset in Rubrix#
First, we load the unsupervised split from the imdb dataset and create a new Rubrix dataset with 100 random examples:
[ ]:
unlabelled = load_dataset("imdb", split="unsupervised").shuffle(seed=42).select(range(100))
unlabelled = rb.DatasetForTextClassification.from_datasets(unlabelled)
rb.log(unlabelled, "imdb_unlabelled")
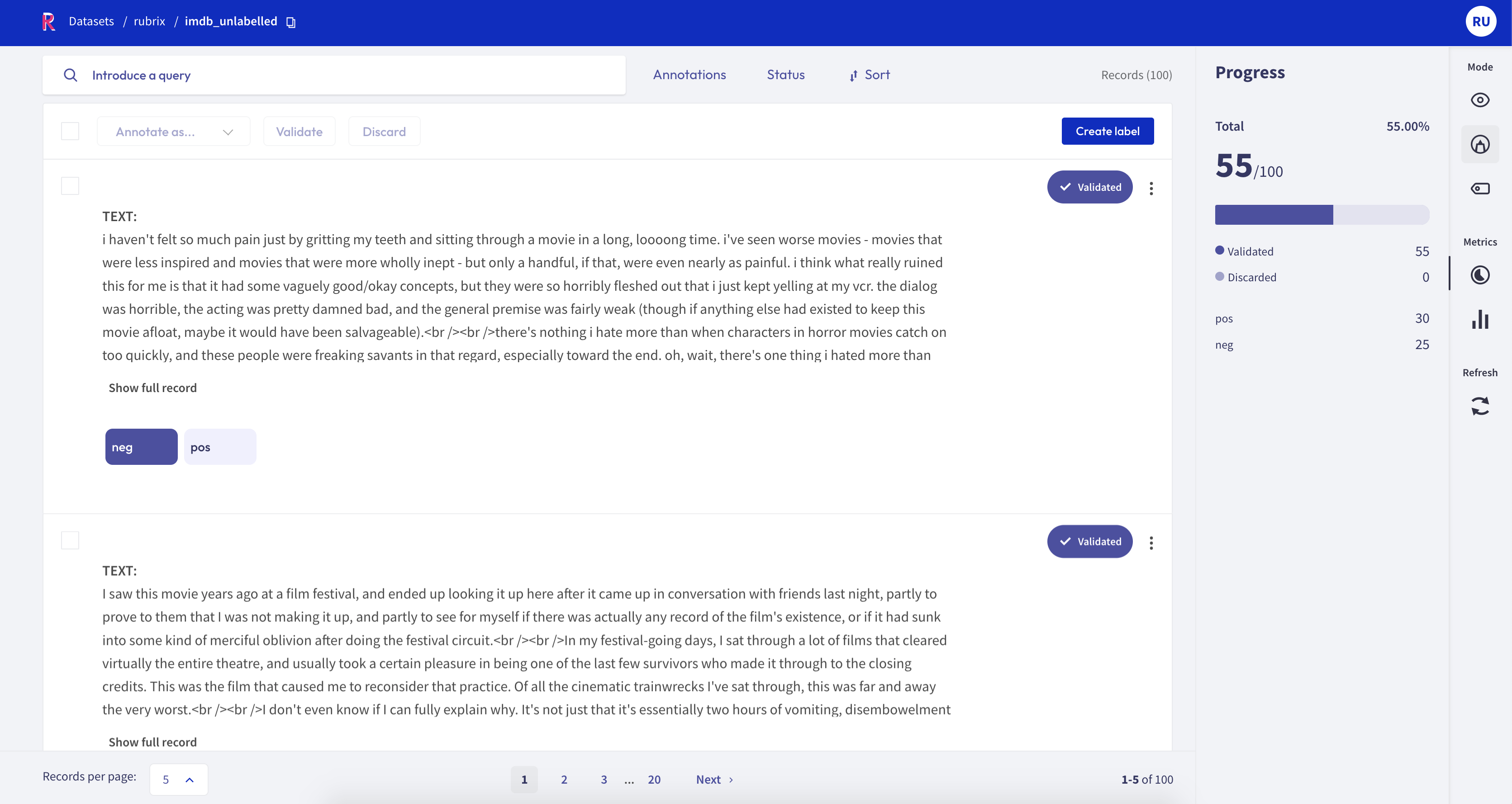
Manual labelling#
In this step, we create the labels pos and neg using the same label scheme as the original dataset. Then we use the UI to sequentially label a few examples. For the example, we spent literally 15 minutes.
Watch the video below to get a sense of the steps and time you need to replicate the results.
Before training, you can easily share the dataset using the push_to_hub method. This might be useful if you don’t have a GPU on your machine and want to use a training service or Colab for example.
[ ]:
rb.load("imdb_unlabelled").prepare_for_training().push_to_hub("mini-imdb")
The dataset is available on the HF hub. You can see the summary in the UI below:
Train and evaluate SetFit model#
Finally, we are ready to test SetFit!
Thanks to Rubrix’s integration with datasets and the Hub, if you don’t have a local GPU you can use this Google Colab to reproduce the training process with the labelled dataset. If you use a GPU runtime, it literally takes 5 minutes to train.
Below we load the dataset from Rubrix, format it for training with transformers, load the full imbd test dataset, load a pre-trained sentence transformers model, train the SetFit model, and evaluate it!
[ ]:
# Load the handlabelled dataset from Rubrix
train_ds = rb.load("imdb_unlabelled").prepare_for_training()
# Load the full imdb test dataset
test_ds = load_dataset("imdb", split="test")
# Load SetFit model from Hub
model = SetFitModel.from_pretrained("sentence-transformers/paraphrase-mpnet-base-v2")
# Create trainer
trainer = SetFitTrainer(
model=model,
train_dataset=train_ds,
eval_dataset=test_ds,
loss_class=CosineSimilarityLoss,
batch_size=16,
num_iterations=20, # The number of text pairs to generate
)
# Train and evaluate
trainer.train()
metrics = trainer.evaluate()
Optionally, you can share your amazing model with the world!
[ ]:
trainer.push_to_hub("setfit-mini-imdb")
Conclusion#
The metrics object should give you around 0.9 accuracy on the full test set 🎉
And remember:
We have manually labelled 55 examples,
We haven’t used a single example from the original training set,
and we’ve trained the model in 5 min!
Now, I don’t think you have any more excuses to not invest some time labeling a few good quality examples!