💾 Monitor predictions in HTTP API endpoints#
In this tutorial, you’ll learn to monitor the predictions of a FastAPI inference endpoint and log model predictions in a Rubrix dataset. It will walk you through 4 basic steps:
💾 Load the model you want to use.
🔄 Convert model output to Rubrix format.
💻 Create a FastAPI endpoint.
🤖 Add middleware to automate logging to Rubrix
Introduction#
Models are often deployed via an HTTP API endpoint that is called by a client to obtain the model’s predictions. With FastAPI and Rubrix you can easily monitor those predictions and log them to a Rubrix dataset. Due to its human-centric UX, Rubrix datasets can be comfortably viewed and explored by any team member of your organization. But Rubrix also provides automatically computed metrics, both of which help you to keep track of your predictor and spot potential issues early on.
FastAPI and Rubrix allow you to deploy and monitor any model you like, but in this tutorial we will focus on the two most common frameworks in the NLP space: spaCy and transformers. Let’s get started!
Setup#
Rubrix is a free and open-source tool to explore, annotate, and monitor data for NLP projects.
If you are new to Rubrix, check out the ⭐ Github repository.
If you have not installed and launched Rubrix yet, check the Setup and Installation guide.
Apart from Rubrix, we’ll need a few third party libraries that can be installed via pip:
[ ]:
%pip install fastapi uvicorn[standard] spacy transformers[torch] -qqq
1. Loading models#
As a first step, let’s load our models. For spacy we need to first download the model before we can instantiate a spacy pipeline with it. Here we use the small English model en_core_web_sm, but you can choose any available model on their hub.
[ ]:
!python -m spacy download en_core_web_sm
[ ]:
import spacy
spacy_pipeline = spacy.load("en_core_web_sm")
The “text-classification” pipeline by transformers download’s the model for you and by default it will use the distilbert-base-uncased-finetuned-sst-2-english model. But you can instantiate the pipeline with any compatible model on their hub.
[ ]:
from transformers import pipeline
transformers_pipeline = pipeline("text-classification", return_all_scores=True)
For more information about using the transformers library with Rubrix, check the tutorial How to label your data and fine-tune a 🤗 sentiment classifier
Model output#
Let’s try the transformer’s pipeline in this example:
[5]:
from pprint import pprint
batch = ['I really like rubrix!']
predictions = transformers_pipeline(batch)
pprint(predictions)
[[{'label': 'NEGATIVE', 'score': 0.0003226407279726118},
{'label': 'POSITIVE', 'score': 0.9996774196624756}]]
Looks like the predictions is a list containing lists of two elements : - The first dictionary containing the NEGATIVE sentiment label and its score. - The second dictionary containing the same data but for POSITIVE sentiment.
2. Convert output to Rubrix format#
To log the output to Rubrix, we should supply a list of dictionaries, each dictionary containing two keys: - labels : value is a list of strings, each string being the label of the sentiment. - scores : value is a list of floats, each float being the probability of the sentiment.
[6]:
rubrix_format = [
{
"labels": [p["label"] for p in prediction],
"scores": [p["score"] for p in prediction],
}
for prediction in predictions
]
pprint(rubrix_format)
[{'labels': ['NEGATIVE', 'POSITIVE'],
'scores': [0.0003226407279726118, 0.9996774196624756]}]
3. Create prediction endpoint#
[ ]:
from fastapi import FastAPI
from typing import List
app_transformers = FastAPI()
# prediction endpoint using transformers pipeline
@app_transformers.post("/")
def predict_transformers(batch: List[str]):
predictions = transformers_pipeline(batch)
return [
{
"labels": [p["label"] for p in prediction],
"scores": [p["score"] for p in prediction],
}
for prediction in predictions
]
4. Add Rubrix logging middleware to the application#
[ ]:
from rubrix.monitoring.asgi import RubrixLogHTTPMiddleware
app_transformers.add_middleware(
RubrixLogHTTPMiddleware,
api_endpoint="/transformers/", #the endpoint that will be logged
dataset="monitoring_transformers", #your dataset name
# you could post-process the predict output with a custom record_mapper function
# record_mapper=custom_text_classification_mapper,
)
5. Do the same for spaCy#
We’ll add a custom mapper to convert spaCy’s output to TokenClassificationRecord format
FastAPI application#
[ ]:
from rubrix.monitoring.asgi import RubrixLogHTTPMiddleware, token_classification_mapper
app_spacy = FastAPI()
app_spacy.add_middleware(
RubrixLogHTTPMiddleware,
api_endpoint="/spacy/",
dataset="monitoring_spacy",
records_mapper=token_classification_mapper
)
# prediction endpoint using spacy pipeline
@app_spacy.post("/")
def predict_spacy(batch: List[str]):
predictions = []
for text in batch:
doc = spacy_pipeline(text) # spaCy Doc creation
# Entity annotations
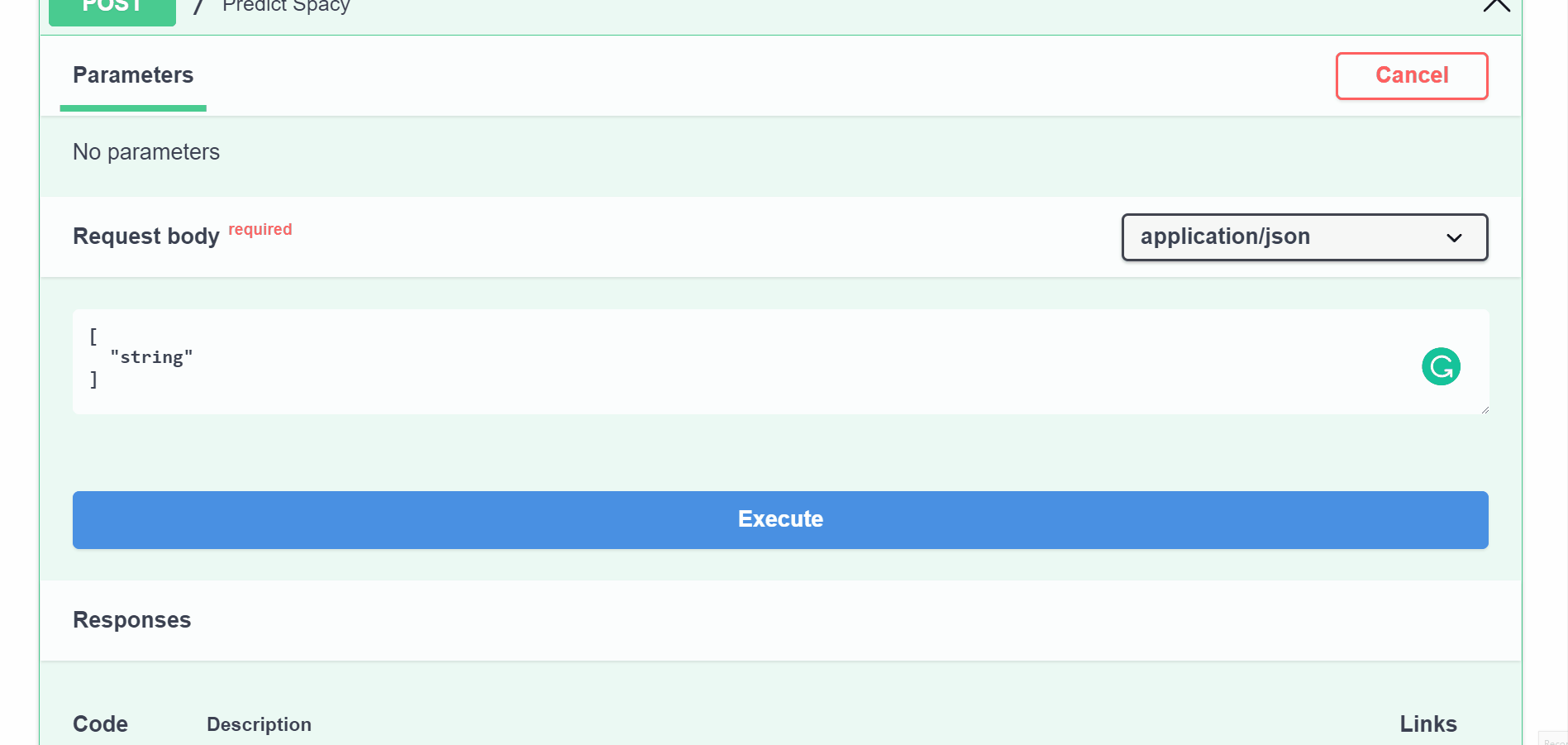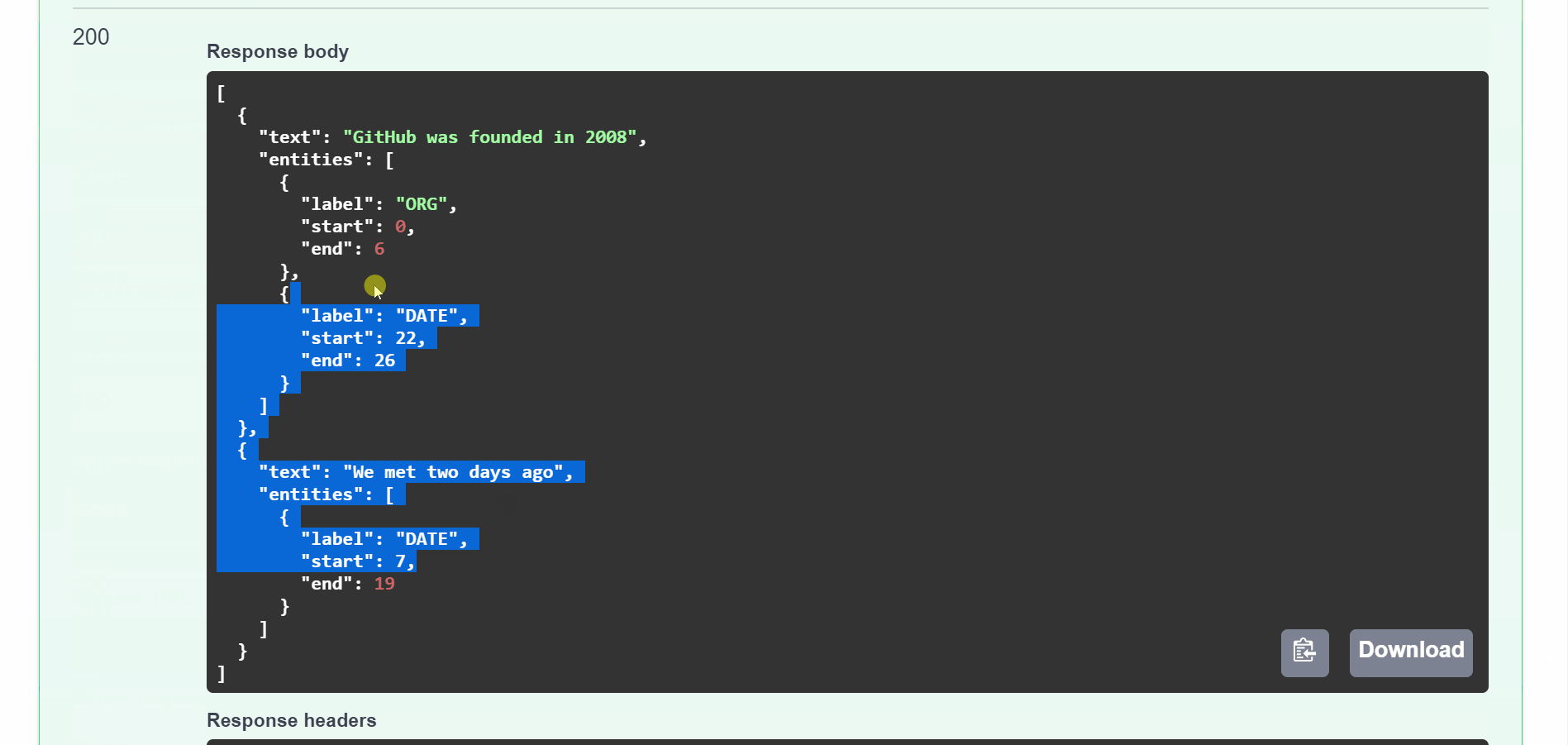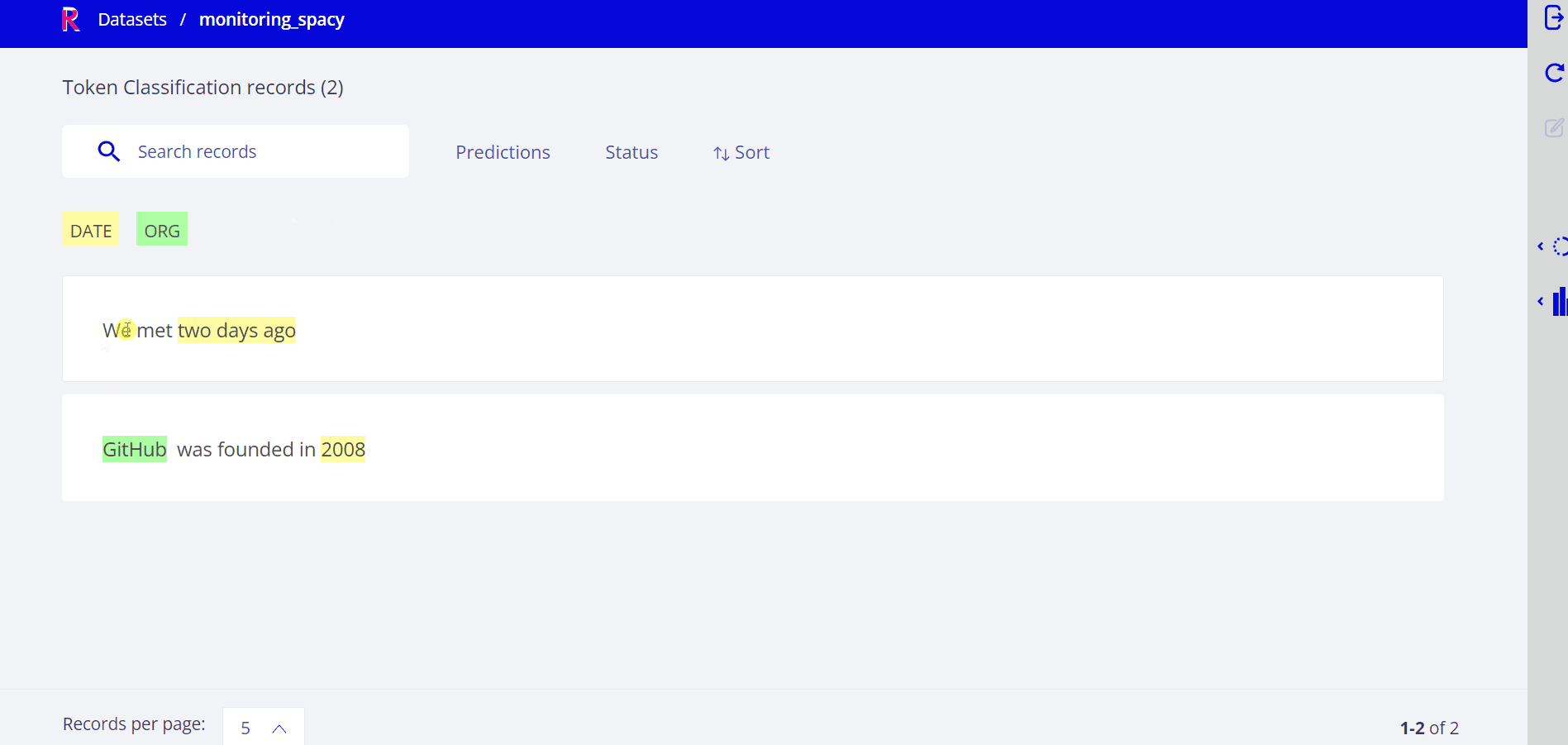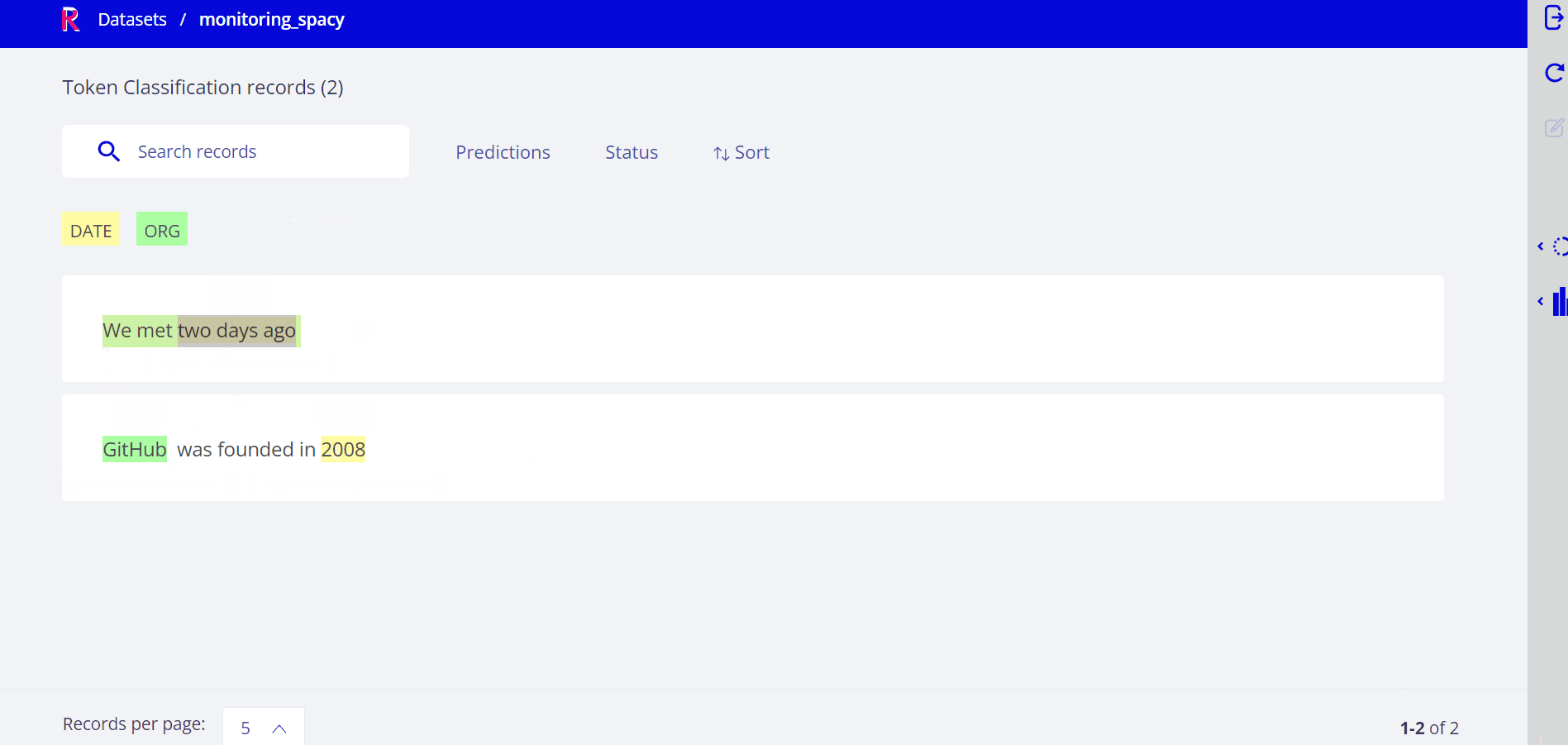
entities = [
{"label": ent.label_, "start": ent.start_char, "end": ent.end_char}
for ent in doc.ents
]
prediction = {
"text": text,
"entities": entities,
}
predictions.append(prediction)
return predictions
6. Putting it all together#
Now we can combine everything in order to see our results!
[ ]:
app = FastAPI()
@app.get("/")
def root():
return {"message": "alive"}
app.mount("/transformers", app_transformers)
app.mount("/spacy", app_spacy)
Launch the application#
To launch the application, copy the whole code into a file named main.py and run the following command:
[ ]:
!uvicorn main:app
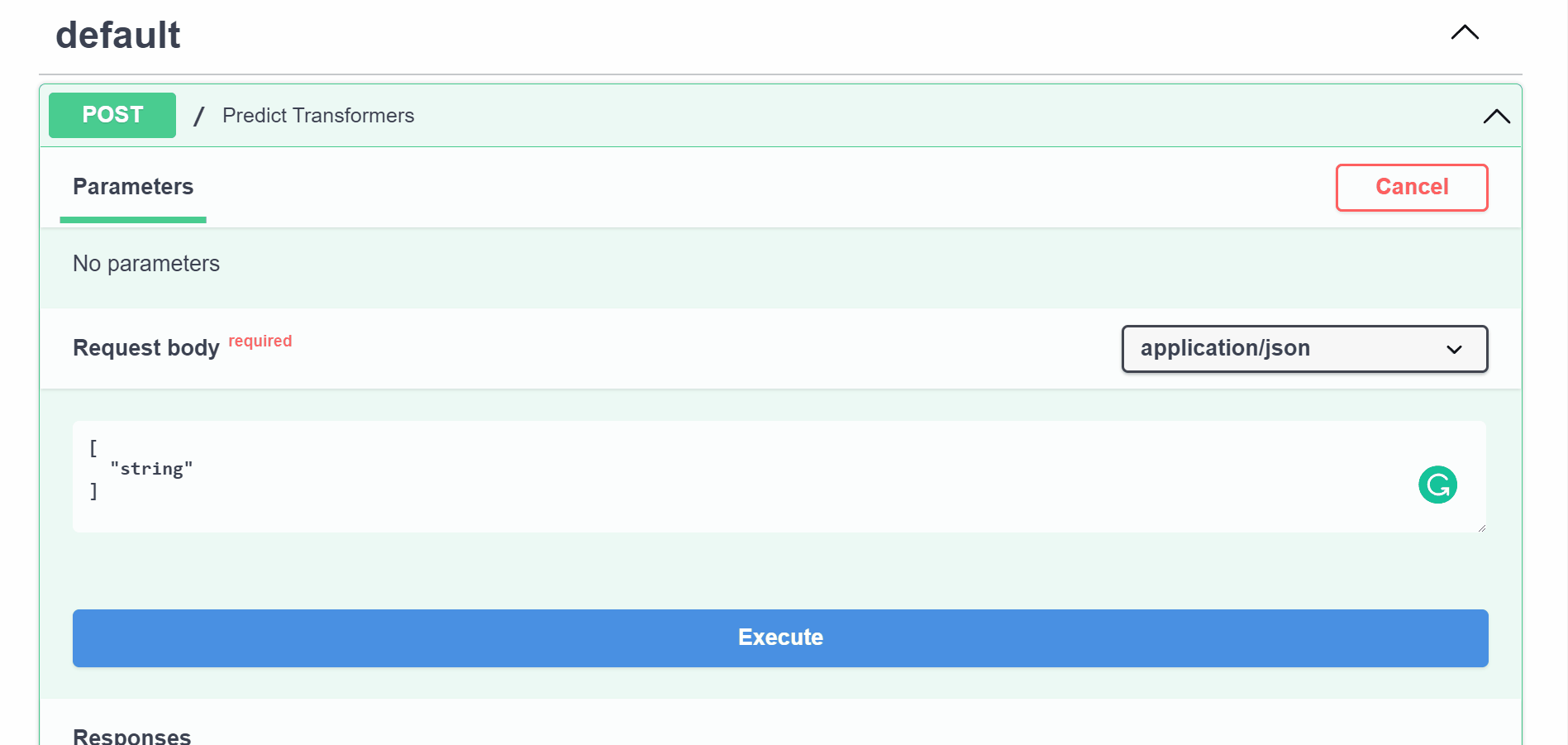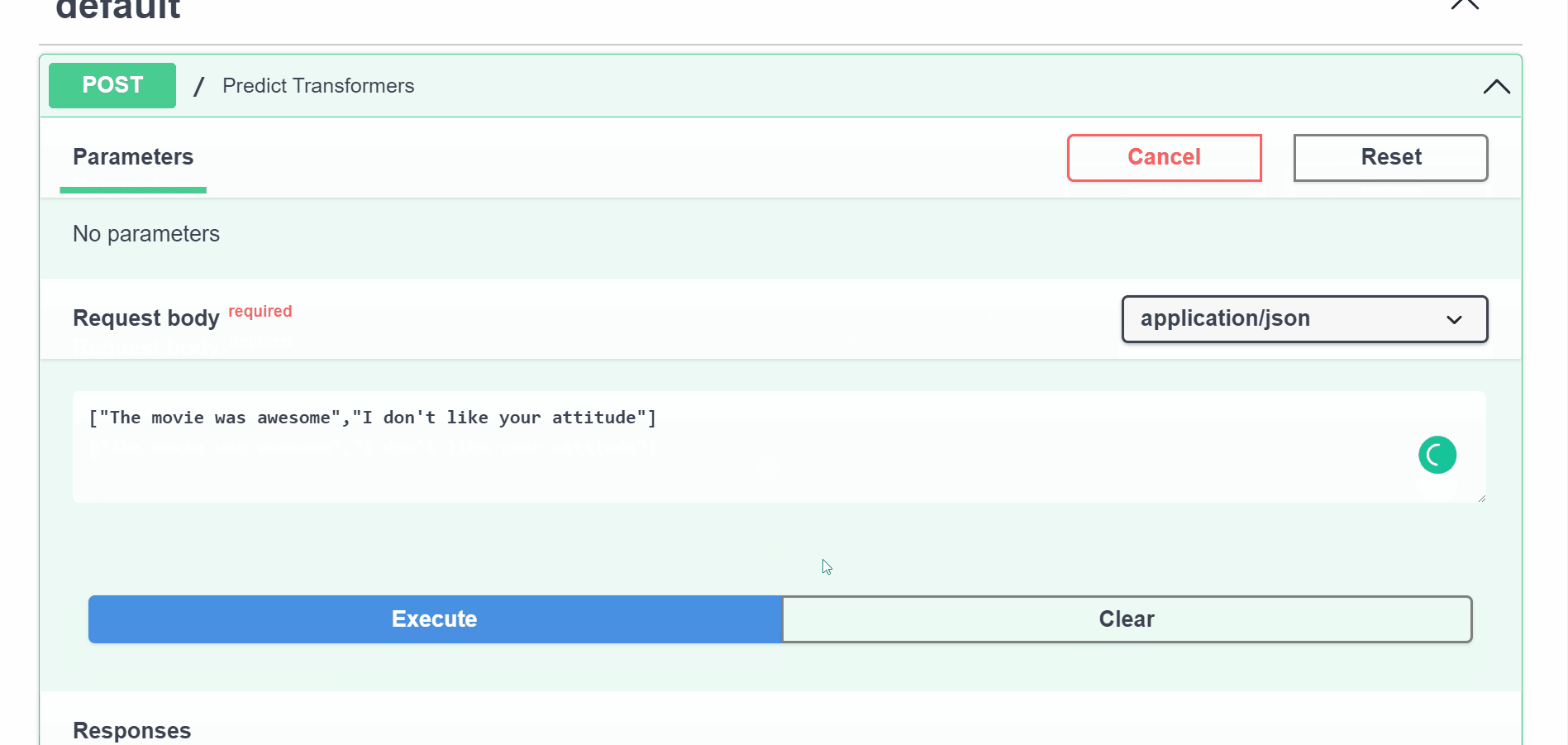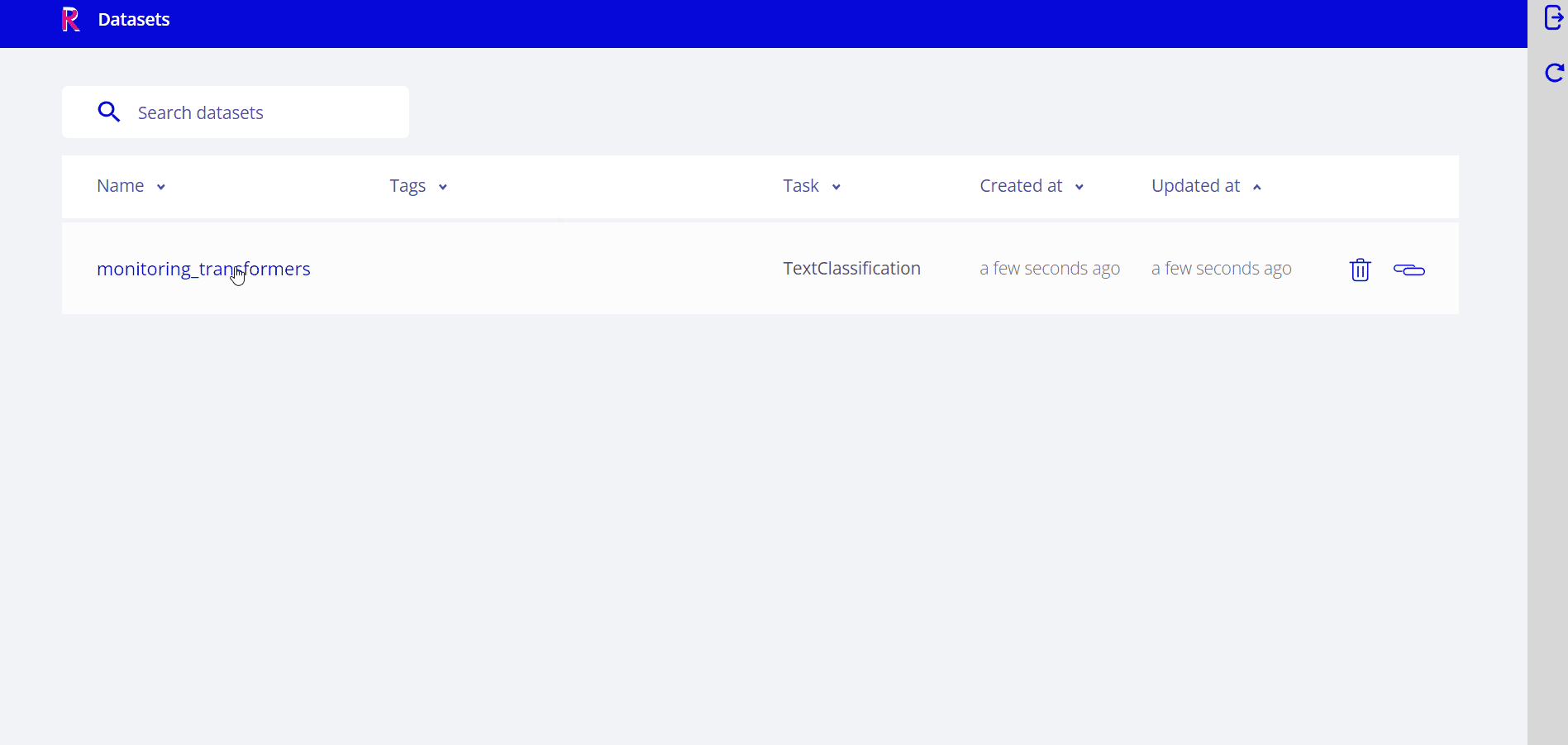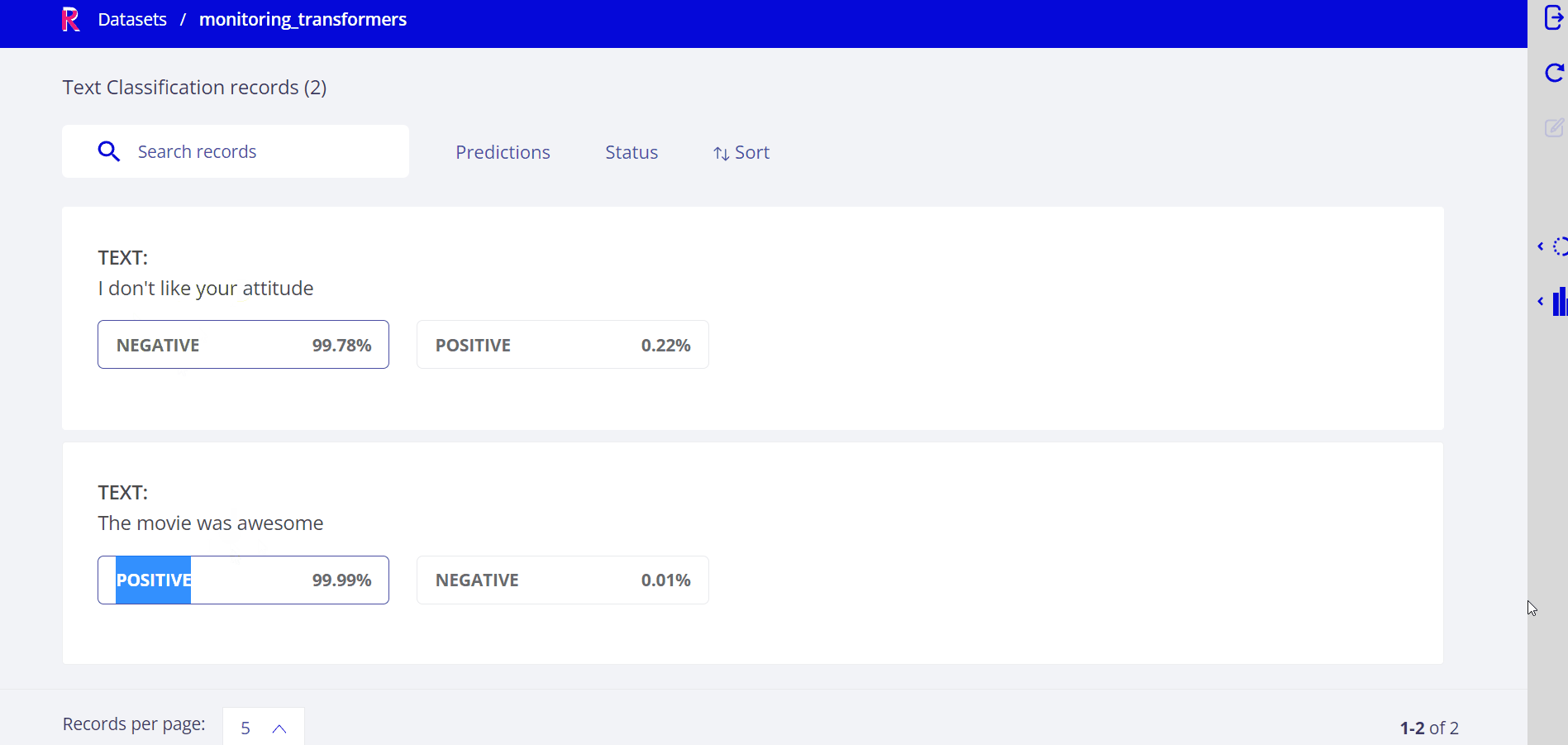
Transformers demo#
spaCy demo#
Summary#
In this tutorial, we learned to automatically log model outputs into Rubrix. This can be used to continuously and transparently monitor HTTP inference endpoints.
Next steps#
⭐ Rubrix Github repo to stay updated.
📚 Rubrix documentation for more guides and tutorials.
🙋♀️ Join the Rubrix community! A good place to start is the discussion forum.
[ ]: