Rubrix Cookbook#
This guide is a collection of recipes. It shows examples for using Rubrix with some of the most popular NLP Python libraries.
Rubrix can be used with any library or framework inside your favourite IDE, be it VS Code, or Jupyter Lab.
With these examples, you’ll be able to start exploring and annnotating data with these libraries and get some inspiration if your library of choice is not in this guide.
If you miss a library in this guide that, leave a message in the Rubrix Discussion forum or open an issue or PR, we’ll be very happy to receive contributions.
Hugging Face Transformers#
Hugging Face has made working with NLP easier than ever before. With a few lines of code we can take a pretrained Transformer model from the Hub, start making some predictions and log them into Rubrix.
[ ]:
%pip install torch transformers datasets -qqq
Text Classification#
For text and zeroshot classification pipelines, Rubrix’s rb.monitor method makes it really easy to store data in Rubrix.
Let’s see some examples.
Zero-shot classification pipelines#
Let’s load a zero-shot-classification pipeline:
[ ]:
import rubrix as rb
from transformers import pipeline
nlp = pipeline("zero-shot-classification", model="typeform/distilbert-base-uncased-mnli")
Let’s use the rb.monitor method, which will asynchronously log our pipeline predictions. Now every time we predict with this pipeline the records will be logged in Rubrix. For example the code:
[ ]:
# sample rate = 1 means we'll be logging every prediction
# for monitoring production models a lower rate might be preferable
nlp = rb.monitor(nlp, dataset="zeroshot_example", sample_rate=1)
nlp("this is a test", candidate_labels=['World', 'Sports', 'Business', 'Sci/Tech'])
It will create the following dataset:

which contains the following record:
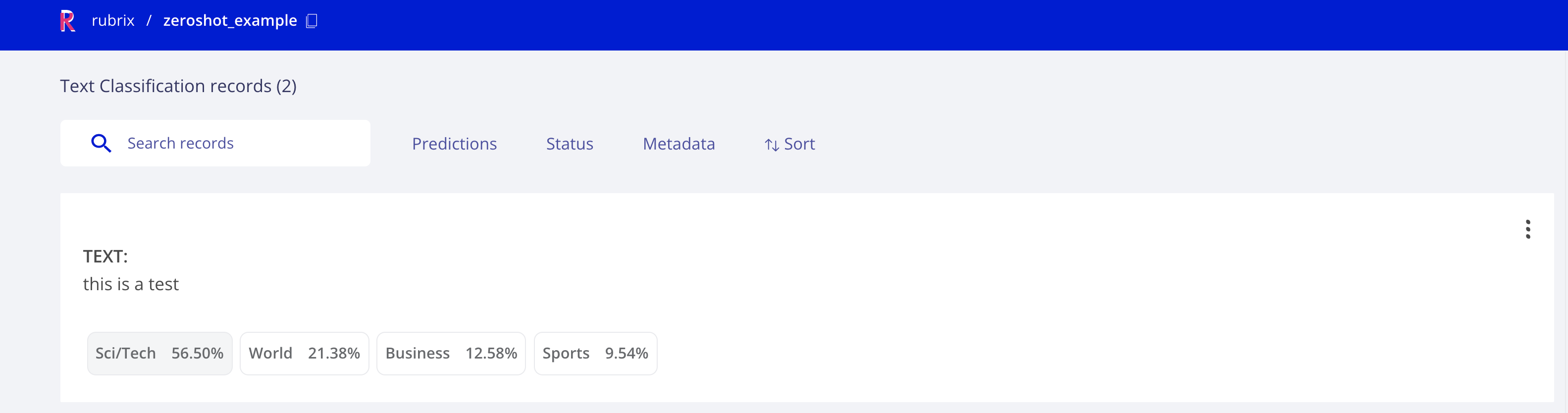
Now if we want to log a larger dataset we can use the batch prediction method from pipelines in a similar way. Let’s load a dataset from the Hugging Face Hub and use the dataset.map method to parallelize the inference. The following will log the predictions for the first 20 records in the ag_news test dataset. You can use the same idea for any custom dataset, using pandas.read_csv for example.
[ ]:
from datasets import load_dataset
dataset = load_dataset("ag_news", split="test[0:20]")
dataset.map(
lambda examples: {"predictions": nlp(examples["text"], candidate_labels=['World', 'Sports', 'Business', 'Sci/Tech'])},
batch_size=5,
batched=True
)
Text classification pipelines#
For text classification pipelines it will work in the same way as above. Let’s see an example, this time using pandas.
Let’s read a dataset with tweets:
[2]:
import pandas as pd
# a url to a dataset containing tweets
url = "https://raw.githubusercontent.com/ajayshewale/Sentiment-Analysis-of-Text-Data-Tweets-/master/data/test.csv"
df = pd.read_csv(url)
df.head()
[2]:
| Id | Category | |
|---|---|---|
| 0 | 6.289494e+17 | dear @Microsoft the newOoffice for Mac is grea... |
| 1 | 6.289766e+17 | @Microsoft how about you make a system that do... |
| 2 | 6.290232e+17 | Not Available |
| 3 | 6.291792e+17 | Not Available |
| 4 | 6.291863e+17 | If I make a game as a #windows10 Universal App... |
And use a sentiment analysis pipeline with the rb.monitor method:
[ ]:
nlp = pipeline("sentiment-analysis")
nlp = rb.monitor(nlp, dataset="text_classification_example", sample_rate=1)
for i,example in df.iterrows():
nlp(example.Category)
which will create the following dataset:

Training#
The above examples have shown how to store data in Rubrix, using pre-trained models. You can use Rubrix for storing datasets without predictions and without annotations, or a combination of both annotations and predictions.
One of the main features of Rubrix is data annotation, which lets you rapidly create training sets. In this example, let’s see how we can take labelled dataset from Rubrix to fine-tune a Hugging Face transformers text classifier.
Let’s read a Rubrix dataset, prepare a training set and use the Trainer API for fine-tuning a distilbert-base-uncased model.
Take into account that a zeroshot_example contains annotations. You can go to this dataset (if you have run the previous example) and do some manual annotation using the Annotation mode.
[8]:
from datasets import Dataset
import rubrix as rb
# load rubrix dataset
dataset_rb = rb.load('zeroshot_example')
# create 🤗 dataset with text and labels as numeric ids
train_ds = dataset_rb.prepare_for_training()
[ ]:
from transformers import AutoModelForSequenceClassification
from transformers import AutoTokenizer
from transformers import Trainer
# from here, it's just regular fine-tuning with 🤗 transformers
tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
model = AutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased", num_labels=4)
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
train_dataset = train_ds.map(tokenize_function, batched=True).shuffle(seed=42)
trainer = Trainer(model=model, train_dataset=train_dataset)
trainer.train()
Token Classification#
We will explore a DistilBERT NER classifier fine-tuned for NER using the conll03 English dataset.
[ ]:
import rubrix as rb
from transformers import pipeline
input_text = "My name is Sarah and I live in London"
# We define our HuggingFace Pipeline
classifier = pipeline(
"ner",
model="elastic/distilbert-base-cased-finetuned-conll03-english",
)
# Making the prediction
predictions = classifier(input_text, aggregation_strategy="first")
# Creating the predicted entities as a list of tuples (entity, start_char, end_char)
prediction = [(pred["entity_group"], pred["start"], pred["end"]) for pred in predictions]
# Create word tokens
batch_encoding = classifier.tokenizer(input_text)
word_ids = sorted(set(batch_encoding.word_ids()) - {None})
words = []
for word_id in word_ids:
char_span = batch_encoding.word_to_chars(word_id)
words.append(input_text[char_span.start:char_span.end])
# Building a TokenClassificationRecord
record = rb.TokenClassificationRecord(
text=input_text,
tokens=words,
prediction=prediction,
prediction_agent="distilbert-base-cased-finetuned-conll03-english",
)
# Logging into Rubrix
rb.log(records=record, name="zeroshot-ner")
Fine-tuning with custom annotations#
Let’s see how we can use this model to pre-annotate a custom dataset and fine-tune a small transformer model. As custom dataset, we will take the well known AG news dataset that is normally used for benchmarking text classification models.
[ ]:
from datasets import load_dataset
from transformers import pipeline
import rubrix as rb
from tqdm.auto import tqdm
# Our custom dataset will consist of the first 'n' examples of the AG news dataset.
n = 1000
ag_news = load_dataset("ag_news", split="train", streaming=True)
# Our pre-annotations will come from a fine-tuned distilbert model
classifier = pipeline("ner", "elastic/distilbert-base-cased-finetuned-conll03-english")
# For our annotation process we want word tokens, NOT subword tokens
def make_tokens(examples):
batch_encoding = classifier.tokenizer(examples["text"])
examples["tokens"] = []
for text, encoding in zip(examples["text"], batch_encoding.encodings):
word_ids = sorted(set(encoding.word_ids) - {None})
words = []
for word_id in word_ids:
start, end = encoding.word_to_chars(word_id)
words.append(text[start:end])
examples["tokens"].append(words)
return examples
# Get the prediction from our fine-tuned distilbert
def make_predictions(examples):
examples["prediction"] = classifier(examples["text"], aggregation_strategy="first")
return examples
# Add tokens and predictions
ag_news_prepared = ag_news.take(n)\
.map(make_tokens, batched=True)\
.map(make_predictions, batched=True, batch_size=32)
# Make Rubrix records
records = []
for idx, example in tqdm(enumerate(ag_news_prepared), total=n, desc="Making records"):
record = rb.TokenClassificationRecord(
text=example["text"],
tokens=example["tokens"],
prediction=[(p["entity_group"], p["start"], p["end"]) for p in example["prediction"]],
prediction_agent="elastic/distilbert-base-cased-finetuned-conll03-english",
id=idx,
)
records.append(record)
# Upload records to Rubrix
rb.log(records, "ag_news_ner")
After adding the records to Rubrix, we can now annotate them in the web app with the help of the predictions. Afterward, we load them back into the notebook and fine-tune our model. We chose the very efficient and light-weight ELECTRA model to illustrate the procedure.
Following training steps are a copy&paste of the excellent Hugging Face How-to guides. Check them for more information about the training process.
[ ]:
from transformers import AutoTokenizer, DataCollatorForTokenClassification
# Load the dataset from the web app and prepare it for training a Hugging Face transformer
agnews_ds = rb.load("ag_news_ner").prepare_for_training()
# Split it into a train and test set
agnews = agnews_ds.train_test_split()
# We need to properly tokenize our data and align our labels
tokenizer = AutoTokenizer.from_pretrained("google/electra-small-discriminator")
data_collator = DataCollatorForTokenClassification(tokenizer=tokenizer)
def tokenize_and_align_labels(examples):
tokenized_inputs = tokenizer(examples["tokens"], truncation=True, is_split_into_words=True)
labels = []
for i, label in enumerate(examples["ner_tags"]):
word_ids = tokenized_inputs.word_ids(batch_index=i) # Map tokens to their respective word.
previous_word_idx = None
label_ids = []
for word_idx in word_ids: # Set the special tokens to -100.
if word_idx is None:
label_ids.append(-100)
elif word_idx != previous_word_idx: # Only label the first token of a given word.
label_ids.append(label[word_idx])
else:
label_ids.append(-100)
previous_word_idx = word_idx
labels.append(label_ids)
tokenized_inputs["labels"] = labels
return tokenized_inputs
tokenized_agnews = agnews.map(tokenize_and_align_labels, batched=True)
[ ]:
from transformers import AutoModelForTokenClassification, TrainingArguments, Trainer
# Load the pre-trained transformer and provide the dimensions of your token classification head
model = AutoModelForTokenClassification.from_pretrained(
"google/electra-small-discriminator",
num_labels=len(agnews_ds.features["ner_tags"][0].names)
)
# Define your training arguments
training_args = TrainingArguments(
output_dir="./results",
evaluation_strategy="epoch",
learning_rate=2e-5,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
num_train_epochs=3,
weight_decay=0.01,
)
# Instantiate the trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_agnews["train"],
eval_dataset=tokenized_agnews["test"],
tokenizer=tokenizer,
data_collator=data_collator,
)
# Train the model
trainer.train()
spaCy#
spaCy offers industrial-strength Natural Language Processing, with support for 64+ languages, trained pipelines, multi-task learning with pretrained Transformers, pretrained word vectors and much more.
[ ]:
%pip install spacy
Token Classification#
We will focus our spaCy recipes into Token Classification tasks, showing you how to log data from NER and POS tagging.
NER#
For this recipe, we are going to try the French language model to extract NER entities from some sentences.
[ ]:
!python -m spacy download fr_core_news_sm
[ ]:
import rubrix as rb
import spacy
input_text = "Paris a un enfant et la forêt a un oiseau ; l’oiseau s’appelle le moineau ; l’enfant s’appelle le gamin"
# Loading spaCy model
nlp = spacy.load("fr_core_news_sm")
# Creating spaCy doc
doc = nlp(input_text)
# Creating the prediction entity as a list of tuples (entity, start_char, end_char)
prediction = [(ent.label_, ent.start_char, ent.end_char) for ent in doc.ents]
# Building TokenClassificationRecord
record = rb.TokenClassificationRecord(
text=input_text,
tokens=[token.text for token in doc],
prediction=prediction,
prediction_agent="spacy.fr_core_news_sm",
)
# Logging into Rubrix
rb.log(records=record, name="lesmiserables-ner")
POS tagging#
Changing very few parameters, we can make a POS tagging experiment, instead of NER. Let’s try it out with the same input sentence.
[ ]:
import rubrix as rb
import spacy
input_text = "Paris a un enfant et la forêt a un oiseau ; l’oiseau s’appelle le moineau ; l’enfant s’appelle le gamin"
# Loading spaCy model
nlp = spacy.load("fr_core_news_sm")
# Creating spaCy doc
doc = nlp(input_text)
# Creating the prediction entity as a list of tuples (tag, start_char, end_char)
prediction = [(token.pos_, token.idx, token.idx + len(token)) for token in doc]
# Building TokenClassificationRecord
record = rb.TokenClassificationRecord(
text=input_text,
tokens=[token.text for token in doc],
prediction=prediction,
prediction_agent="spacy.fr_core_news_sm",
)
# Logging into Rubrix
rb.log(records=record, name="lesmiserables-pos")
Train a spaCy model by exporting to Docbin#
With the examples above, we have been able to store from spaCy models into Rubrix.
In order to train models with spaCy, Rubrix provides you with an easy util to prepare a dataset spaCy Docbin format. With the example below, you can export your Rubrix dataset into a Docbin, save it to disk, and then use this file with the spacy train command.
[ ]:
import spacy
import rubrix as rb
from datasets import load_dataset
# Dataset loading to export it as a Docbin
dataset_raw = load_dataset("conll2003", split="train")
dataset_rubrix = rb.DatasetForTokenClassification.from_datasets(dataset_raw, tags="ner_tags")
# Loading an spaCy blank language model to create the Docbin, as it works faster
nlp = spacy.blank("en")
# After this line, the file will be stored in disk
dataset_rubrix.prepare_for_training(framework="spacy", lang=nlp).to_disk("train.spacy")
Flair#
It’s a framework that provides a state-of-the-art NLP library, a text embedding library and a PyTorch framework for NLP. Flair offers sequence tagging language models in English, Spanish, Dutch, German and many more, and they are also hosted on HuggingFace Model Hub.
[ ]:
%pip install flair
Token Classification (NER)#
Inference#
[ ]:
import rubrix as rb
from flair.data import Sentence
from flair.models import SequenceTagger
# load tagger
tagger = rb.monitor(SequenceTagger.load("flair/ner-english"), dataset="flair-example", sample_rate=1.0)
# make example sentence
sentence = Sentence("George Washington went to Washington")
# predict NER tags. This will log the prediction in Rubrix
tagger.predict(sentence)
Training#
Let’s read a Rubrix dataset, prepare a training set, save to .txt for loading with flair ColumnCorpus and train with flair SequenceTagger
[ ]:
import pandas as pd
from difflib import SequenceMatcher
from flair.data import Corpus
from flair.datasets import ColumnCorpus
from flair.embeddings import WordEmbeddings, FlairEmbeddings, StackedEmbeddings
from flair.models import SequenceTagger
from flair.trainers import ModelTrainer
import rubrix as rb
# 1. Load the dataset from Rubrix (your own NER/token classification task)
# Note: we initiate the 'tars_ner_wnut_17' from "🔫 Zero-shot Named Entity Recognition with Flair" tutorial
# (reference: https://rubrix.readthedocs.io/en/stable/tutorials/08-zeroshot_ner.html)
train_dataset = rb.load("tars_ner_wnut_17").to_pandas()
[ ]:
# 2. Pre-processing to BIO scheme before saving as .txt file
# Use original predictions as annotations for demonstration purposes, in a real use case you would use the `annotations` instead
prediction_list = train_dataset.prediction
text_list = train_dataset.text
annotation_list = []
idx = 0
for ner_list in prediction_list:
new_ner_list = []
for val in ner_list:
new_ner_list.append((text_list[idx][val[1]:val[2]], val[0]))
annotation_list.append(new_ner_list)
idx += 1
ready_data = pd.DataFrame()
ready_data['text'] = text_list
ready_data['annotation'] = annotation_list
def matcher(string, pattern):
'''
Return the start and end index of any pattern present in the text.
'''
match_list = []
pattern = pattern.strip()
seqMatch = SequenceMatcher(None, string, pattern, autojunk=False)
match = seqMatch.find_longest_match(0, len(string), 0, len(pattern))
if (match.size == len(pattern)):
start = match.a
end = match.a + match.size
match_tup = (start, end)
string = string.replace(pattern, "X" * len(pattern), 1)
match_list.append(match_tup)
return match_list, string
def mark_sentence(s, match_list):
'''
Marks all the entities in the sentence as per the BIO scheme.
'''
word_dict = {}
for word in s.split():
word_dict[word] = 'O'
for start, end, e_type in match_list:
temp_str = s[start:end]
tmp_list = temp_str.split()
if len(tmp_list) > 1:
word_dict[tmp_list[0]] = 'B-' + e_type
for w in tmp_list[1:]:
word_dict[w] = 'I-' + e_type
else:
word_dict[temp_str] = 'B-' + e_type
return word_dict
def create_data(df, filepath):
'''
The function responsible for the creation of data in the said format.
'''
with open(filepath, 'w') as f:
for text, annotation in zip(df.text, df.annotation):
text_ = text
match_list = []
for i in annotation:
a, text_ = matcher(text, i[0])
match_list.append((a[0][0], a[0][1], i[1]))
d = mark_sentence(text, match_list)
for i in d.keys():
f.writelines(i + ' ' + d[i] + '\n')
f.writelines('\n')
# path to save the txt file.
filepath = 'train.txt'
# creating the file.
create_data(ready_data, filepath)
[ ]:
# 3. Load to Flair ColumnCorpus
# define columns
columns = {0: 'text', 1: 'ner'}
# directory where the data resides
data_folder = './'
# initializing the corpus
corpus: Corpus = ColumnCorpus(data_folder, columns,
train_file='train.txt',
test_file=None,
dev_file=None)
# 4. Define training parameters
# tag to predict
label_type = 'ner'
# make tag dictionary from the corpus
label_dict = corpus.make_label_dictionary(label_type=label_type)
# initialize embeddings
embedding_types = [
WordEmbeddings('glove'),
FlairEmbeddings('news-forward'),
FlairEmbeddings('news-backward'),
]
embeddings: StackedEmbeddings = StackedEmbeddings(
embeddings=embedding_types)
# 5. initialize sequence tagger
tagger = SequenceTagger(hidden_size=256,
embeddings=embeddings,
tag_dictionary=label_dict,
tag_type=label_type,
use_crf=True)
# 6. initialize trainer
trainer = ModelTrainer(tagger, corpus)
# 7. start training
trainer.train('token-classification',
learning_rate=0.1,
mini_batch_size=32,
max_epochs=15)
Text Classification#
Training#
Let’s read a Rubrix dataset, prepare a training set, save to .csv for loading with flair CSVClassificationCorpus and train with flair ModelTrainer
[ ]:
import pandas as pd
import torch
from torch.optim.lr_scheduler import OneCycleLR
from flair.datasets import CSVClassificationCorpus
from flair.embeddings import TransformerDocumentEmbeddings
from flair.models import TextClassifier
from flair.trainers import ModelTrainer
import rubrix as rb
# 1. Load the dataset from Rubrix
limit_num = 2048
train_dataset = rb.load("tweet_eval_emojis", limit=limit_num).to_pandas()
# 2. Pre-processing training pandas dataframe
train_df = pd.DataFrame()
train_df['text'] = train_dataset['text']
train_df['label'] = train_dataset['annotation']
# 3. Save as csv with tab delimiter
train_df.to_csv('train.csv', sep='\t')
[ ]:
# 4. Read the with CSVClassificationCorpus
data_folder = './'
# column format indicating which columns hold the text and label(s)
label_type = "label"
column_name_map = {1: "text", 2: "label"}
corpus = CSVClassificationCorpus(
data_folder, column_name_map, skip_header=True, delimiter='\t', label_type=label_type)
# 5. create the label dictionary
label_dict = corpus.make_label_dictionary(label_type=label_type)
# 6. initialize transformer document embeddings (many models are available)
document_embeddings = TransformerDocumentEmbeddings(
'distilbert-base-uncased', fine_tune=True)
# 7. create the text classifier
classifier = TextClassifier(
document_embeddings, label_dictionary=label_dict, label_type=label_type)
# 8. initialize trainer with AdamW optimizer
trainer = ModelTrainer(classifier, corpus, optimizer=torch.optim.AdamW)
# 9. run training with fine-tuning
trainer.train('./emojis-classification',
learning_rate=5.0e-5,
mini_batch_size=4,
max_epochs=4,
scheduler=OneCycleLR,
embeddings_storage_mode='none',
weight_decay=0.,
)
Let’s make a prediction with flair TextClassifier
[ ]:
from flair.data import Sentence
from flair.models import TextClassifier
classifier = TextClassifier.load('./emojis-classification/best-model.pt')
# create example sentence
sentence = Sentence('Farewell, Charleston! The memories are sweet #mimosa #dontwannago @ Virginia on King')
# predict class and print
classifier.predict(sentence)
print(sentence.labels)
Zero-shot and Few-shot classifiers#
Flair enables you to use few-shot and zero-shot learning for text classification with Task-aware representation of sentences (TARS), introduced by Halder et al. (2020), see Flair’s documentation for more details.
Let’s see an example of the base zero-shot TARS model:
[ ]:
import rubrix as rb
from flair.models import TARSClassifier
from flair.data import Sentence
# Load our pre-trained TARS model for English
tars = TARSClassifier.load('tars-base')
# Define labels
labels = ["happy", "sad"]
# Create a sentence
text = "I am so glad you liked it!"
sentence = Sentence(text)
# Predict for these labels
tars.predict_zero_shot(sentence, labels)
# Creating the prediction entity as a list of tuples (label, probability)
prediction = [(pred.value, pred.score) for pred in sentence.labels]
# Building a TextClassificationRecord
record = rb.TextClassificationRecord(
text=text,
prediction=prediction,
prediction_agent="tars-base",
)
# Logging into Rubrix
rb.log(records=record, name="en-emotion-zeroshot")
Custom and pre-trained classifiers#
Let’s see an example with the German offensive language classifier
[ ]:
import rubrix as rb
from flair.models import TextClassifier
from flair.data import Sentence
text = "Du erzählst immer Quatsch."
# Load our pre-trained classifier
classifier = TextClassifier.load("de-offensive-language")
# Creating Sentence object
sentence = Sentence(text)
# Make the prediction
classifier.predict(sentence, return_probabilities_for_all_classes=True)
# Creating the prediction entity as a list of tuples (label, probability)
prediction = [(pred.value, pred.score) for pred in sentence.labels]
# Building a TextClassificationRecord
record = rb.TextClassificationRecord(
text=text,
prediction=prediction,
prediction_agent="de-offensive-language",
)
# Logging into Rubrix
rb.log(records=record, name="german-offensive-language")
POS tagging#
In the following snippet we will use de multilingual POS tagging model from Flair.
[ ]:
import rubrix as rb
from flair.data import Sentence
from flair.models import SequenceTagger
input_text = "George Washington went to Washington. Dort kaufte er einen Hut."
# Loading our POS tagging model from flair
tagger = SequenceTagger.load("flair/upos-multi")
# Creating Sentence object
sentence = Sentence(input_text)
# run NER over sentence
tagger.predict(sentence)
# Creating the prediction entity as a list of tuples (entity, start_char, end_char)
prediction = [
(entity.get_labels()[0].value, entity.start_pos, entity.end_pos)
for entity in sentence.get_spans()
]
# Building a TokenClassificationRecord
record = rb.TokenClassificationRecord(
text=input_text,
tokens=[token.text for token in sentence],
prediction=prediction,
prediction_agent="flair/upos-multi",
)
# Logging into Rubrix
rb.log(records=record, name="flair-pos-tagging")
Stanza#
Stanza is a collection of efficient tools for many NLP tasks and processes, all in one library. It’s maintained by the Standford NLP Group. We are going to take a look at a few interactions that can be done with Rubrix.
[ ]:
%pip install stanza
Text Classification#
Let’s start by using a Sentiment Analysis model to log some TextClassificationRecords.
[ ]:
import rubrix as rb
import stanza
text = (
"There are so many NLP libraries available, I don't know which one to choose!"
)
# Downloading our model, in case we don't have it cached
stanza.download("en")
# Creating the pipeline
nlp = stanza.Pipeline(lang="en", processors="tokenize,sentiment")
# Analyzing the input text
doc = nlp(text)
# This model returns 0 for negative, 1 for neutral and 2 for positive outcome.
# We are going to log them into Rubrix using a dictionary to translate numbers to labels.
num_to_labels = {0: "negative", 1: "neutral", 2: "positive"}
# Build a prediction entities list
# Stanza, at the moment, only output the most likely label without probability.
# So we will suppouse Stanza predicts the most likely label with 1.0 probability, and the rest with 0.
entities = []
for _, sentence in enumerate(doc.sentences):
for key in num_to_labels:
if key == sentence.sentiment:
entities.append((num_to_labels[key], 1))
else:
entities.append((num_to_labels[key], 0))
# Building a TextClassificationRecord
record = rb.TextClassificationRecord(
text=text,
prediction=entities,
prediction_agent="stanza/en",
)
# Logging into Rubrix
rb.log(records=record, name="stanza-sentiment")
Token Classification#
Stanza offers so many different pretrained language models for Token Classification Tasks, and the list does not stop growing.
POS tagging#
We can use one of the many UD models, used for POS tags, morphological features and syntantic relations. UD stands for Universal Dependencies, the framework where these models has been trained. For this example, let’s try to extract POS tags of some Catalan lyrics.
[ ]:
import rubrix as rb
import stanza
# Loading a cool Obrint Pas lyric
input_text = "Viure sempre corrent, avançant amb la gent, rellevant contra el vent, transportant sentiments."
# Downloading our model, in case we don't have it cached
stanza.download("ca")
# Creating the pipeline
nlp = stanza.Pipeline(lang="ca", processors="tokenize,mwt,pos")
# Analyzing the input text
doc = nlp(input_text)
# Creating the prediction entity as a list of tuples (tag, start_char, end_char)
prediction = [
(word.pos, token.start_char, token.end_char)
for sent in doc.sentences
for token in sent.tokens
for word in token.words
]
# Building a TokenClassificationRecord
record = rb.TokenClassificationRecord(
text=input_text,
tokens=[word.text for sent in doc.sentences for word in sent.words],
prediction=prediction,
prediction_agent="stanza/catalan",
)
# Logging into Rubrix
rb.log(records=record, name="stanza-catalan-pos")
NER#
Stanza also offers a list of available pretrained models for NER tasks. So, let’s try Russian
[ ]:
import rubrix as rb
import stanza
input_text = (
"Герра-и-Пас - одна из моих любимых книг" # War and Peace is one my favourite books
)
# Downloading our model, in case we don't have it cached
stanza.download("ru")
# Creating the pipeline
nlp = stanza.Pipeline(lang="ru", processors="tokenize,ner")
# Analyzing the input text
doc = nlp(input_text)
# Creating the prediction entity as a list of tuples (entity, start_char, end_char)
prediction = [
(token.ner, token.start_char, token.end_char)
for sent in doc.sentences
for token in sent.tokens
]
# Building a TokenClassificationRecord
record = rb.TokenClassificationRecord(
text=input_text,
tokens=[word.text for sent in doc.sentences for word in sent.words],
prediction=prediction,
prediction_agent="flair/russian",
)
# Logging into Rubrix
rb.log(records=record, name="stanza-russian-ner")