🐠 Human-in-the-loop weak supervision with snorkel¶
This tutorial will walk you through the process of using Rubrix to improve weak supervision and data programming workflows with the amazing Snorkel library.

Introduction¶
Our goal is to show you how you can incorporate Rubrix into data programming workflows to programatically build training data with a human-in-the-loop approach. We will use the widely-known Snorkel library, but a similar approach can be used with other data augmentation libraries such as Textattack or nlpaug.
What is weak supervision? and Snorkel?¶
Weak supervision is a branch of machine learning based on getting lower quality labels more efficiently. We can achieve this by using Snorkel, a library for programmatically building and managing training datasets without manual labeling.
This tutorial¶
In this tutorial, we’ll follow the Spam classification tutorial from Snorkel’s documentation and show you how to extend weak supervision workflows with Rubrix.
The tutorial is organized into:
Spam classification with Snorkel: we provide a brief overview of the tutorial
Extending and finding labeling functions with Rubrix: we analyze different strategies for extending the proposed labeling functions and for exploring new labeling functions
Install Snorkel, Textblob and spaCy¶
[ ]:
%pip install snorkel textblob spacy -qqq
[ ]:
!python -m spacy download en_core_web_sm -qqq
Setup Rubrix¶
If you are new to Rubrix, visit and ⭐ star Rubrix for more materials like and detailed docs: Github repo
If you have not installed and launched Rubrix, check the Setup and Installation guide.
Once installed, you only need to import Rubrix:
[1]:
import rubrix as rb
1. Spam classification with Snorkel¶
Rubrix allows you to log and track data for different NLP tasks (such as Token Classification or Text Classification).
In this tutorial, we will use the YouTube Spam Collection dataset which a binary classification task for detecting spam comments in youtube videos.
The dataset¶
We have a training set and and a test set. The first one does not include the label of the samples and it is set to -1. The test set contains ground-truth labels from the original dataset, where the label is set to 1 if it’s considered SPAM and 0 for HAM.
In this tutorial we’ll be using Snorkel’s data programming methods for programatically building a training set with the help of Rubrix for analizing and reviewing data. We’ll then train a model with this train set and evaluate it against the test set.
Let’s load it in Pandas and take a look!
[3]:
import pandas as pd
df_train = pd.read_csv('data/yt_comments_train.csv')
df_test = pd.read_csv('data/yt_comments_test.csv')
display(df_train)
display(df_test)
| Unnamed: 0 | author | date | text | label | video | |
|---|---|---|---|---|---|---|
| 0 | 0 | Alessandro leite | 2014-11-05T22:21:36 | pls http://www10.vakinha.com.br/VaquinhaE.aspx... | -1.0 | 1 |
| 1 | 1 | Salim Tayara | 2014-11-02T14:33:30 | if your like drones, plz subscribe to Kamal Ta... | -1.0 | 1 |
| 2 | 2 | Phuc Ly | 2014-01-20T15:27:47 | go here to check the views :3 | -1.0 | 1 |
| 3 | 3 | DropShotSk8r | 2014-01-19T04:27:18 | Came here to check the views, goodbye. | -1.0 | 1 |
| 4 | 4 | css403 | 2014-11-07T14:25:48 | i am 2,126,492,636 viewer :D | -1.0 | 1 |
| ... | ... | ... | ... | ... | ... | ... |
| 1581 | 443 | Themayerlife | NaN | Check out my mummy chanel! | -1.0 | 4 |
| 1582 | 444 | Fill Reseni | 2015-05-27T17:10:53.724000 | The rap: cool Rihanna: STTUUPID | -1.0 | 4 |
| 1583 | 445 | Greg Fils Aimé | NaN | I hope everyone is in good spirits I'm a h... | -1.0 | 4 |
| 1584 | 446 | Lil M | NaN | Lil m !!!!! Check hi out!!!!! Does live the wa... | -1.0 | 4 |
| 1585 | 447 | AvidorFilms | NaN | Please check out my youtube channel! Just uplo... | -1.0 | 4 |
1586 rows × 6 columns
| Unnamed: 0 | author | date | text | label | video | |
|---|---|---|---|---|---|---|
| 0 | 27 | حلم الشباب | 2015-05-25T23:42:49.533000 | Check out this video on YouTube: | 1 | 5 |
| 1 | 194 | MOHAMED THASLEEM | 2015-05-24T07:03:59.488000 | super music | 0 | 5 |
| 2 | 277 | AlabaGames | 2015-05-22T00:31:43.922000 | Subscribe my channel I RECORDING FIFA 15 GOAL... | 1 | 5 |
| 3 | 132 | Manish Ray | 2015-05-23T08:55:07.512000 | This song is so beauty | 0 | 5 |
| 4 | 163 | Sudheer Yadav | 2015-05-28T10:28:25.133000 | SEE SOME MORE SONG OPEN GOOGLE AND TYPE Shakir... | 1 | 5 |
| ... | ... | ... | ... | ... | ... | ... |
| 245 | 32 | GamezZ MTA | 2015-05-09T00:08:26.185000 | Pleas subscribe my channel | 1 | 5 |
| 246 | 176 | Viv Varghese | 2015-05-25T08:59:50.837000 | The best FIFA world cup song for sure. | 0 | 5 |
| 247 | 314 | yakikukamo FIRELOVER | 2013-07-18T17:07:06.152000 | hey you ! check out the channel of Alvar Lake !! | 1 | 5 |
| 248 | 25 | James Cook | 2013-10-10T18:08:07.815000 | Hello Guys...I Found a Way to Make Money Onlin... | 1 | 5 |
| 249 | 11 | Trulee IsNotAmazing | 2013-09-07T14:18:22.601000 | Beautiful song beautiful girl it works | 0 | 5 |
250 rows × 6 columns
Labeling functions¶
Labeling functions (LFs) are Python function which encode heuristics (such as keywords or pattern matching), distant supervision methods (using external knowledge) or even “low-quality” crowd-worker label datasets. The goal is to create a probabilistic model which is able to combine the output of a set of noisy labels assigned by this LFs. Snorkel provides several strategies for defining and combining LFs, for more information check Snorkel LFs tutorial.
In this tutorial, we will first define the LFs from the Snorkel tutorial and then show you how you can use Rubrix to enhance this type of weak-supervision workflows.
Let’s take a look at the original LFs:
[4]:
import re
from snorkel.labeling import labeling_function, LabelingFunction
from snorkel.labeling.lf.nlp import nlp_labeling_function
from snorkel.preprocess import preprocessor
from snorkel.preprocess.nlp import SpacyPreprocessor
from textblob import TextBlob
ABSTAIN = -1
HAM = 0
SPAM = 1
# Keyword searches
@labeling_function()
def check(x):
return SPAM if "check" in x.text.lower() else ABSTAIN
@labeling_function()
def check_out(x):
return SPAM if "check out" in x.text.lower() else ABSTAIN
# Heuristics
@labeling_function()
def short_comment(x):
"""Ham comments are often short, such as 'cool video!'"""
return HAM if len(x.text.split()) < 5 else ABSTAIN
# List of keywords
def keyword_lookup(x, keywords, label):
if any(word in x.text.lower() for word in keywords):
return label
return ABSTAIN
def make_keyword_lf(keywords, label=SPAM):
return LabelingFunction(
name=f"keyword_{keywords[0]}",
f=keyword_lookup,
resources=dict(keywords=keywords, label=label),
)
"""Spam comments talk about 'my channel', 'my video', etc."""
keyword_my = make_keyword_lf(keywords=["my"])
"""Spam comments ask users to subscribe to their channels."""
keyword_subscribe = make_keyword_lf(keywords=["subscribe"])
"""Spam comments post links to other channels."""
keyword_link = make_keyword_lf(keywords=["http"])
"""Spam comments make requests rather than commenting."""
keyword_please = make_keyword_lf(keywords=["please", "plz"])
"""Ham comments actually talk about the video's content."""
keyword_song = make_keyword_lf(keywords=["song"], label=HAM)
# Pattern matching with regex
@labeling_function()
def regex_check_out(x):
return SPAM if re.search(r"check.*out", x.text, flags=re.I) else ABSTAIN
# Third party models (TextBlob and spaCy)
# TextBlob
@preprocessor(memoize=True)
def textblob_sentiment(x):
scores = TextBlob(x.text)
x.polarity = scores.sentiment.polarity
x.subjectivity = scores.sentiment.subjectivity
return x
@labeling_function(pre=[textblob_sentiment])
def textblob_subjectivity(x):
return HAM if x.subjectivity >= 0.5 else ABSTAIN
@labeling_function(pre=[textblob_sentiment])
def textblob_polarity(x):
return HAM if x.polarity >= 0.9 else ABSTAIN
# spaCy
# There are two different methods to use spaCy:
# Method 1:
spacy = SpacyPreprocessor(text_field="text", doc_field="doc", memoize=True)
@labeling_function(pre=[spacy])
def has_person(x):
"""Ham comments mention specific people and are short."""
if len(x.doc) < 20 and any([ent.label_ == "PERSON" for ent in x.doc.ents]):
return HAM
else:
return ABSTAIN
# Method 2:
@nlp_labeling_function()
def has_person_nlp(x):
"""Ham comments mention specific people."""
if any([ent.label_ == "PERSON" for ent in x.doc.ents]):
return HAM
else:
return ABSTAIN
[5]:
# List of labeling functions proposed at
original_labelling_functions = [
keyword_my,
keyword_subscribe,
keyword_link,
keyword_please,
keyword_song,
regex_check_out,
short_comment,
has_person_nlp,
textblob_polarity,
textblob_subjectivity,
]
We have mentioned multiple functions that could be used to label our data, but we never gave a solution on how to deal with the overlap and conflicts.
To handle this issue, Snorkel provide the LabelModel. You can read more about how it works in the Snorkel tutorial and the documentation.
Let’s just use a LabelModel to test the proposed LFs and let’s wrap it into a function so we can reuse it to evaluate new LFs along the way:
[6]:
from snorkel.labeling import PandasLFApplier
from snorkel.labeling.model import LabelModel
def test_label_model(lfs):
# Apply LFs to datasets
applier = PandasLFApplier(lfs=lfs)
L_train = applier.apply(df=df_train)
L_test = applier.apply(df=df_test)
Y_test = df_test.label.values # y_test labels
label_model = LabelModel(cardinality=2, verbose=True) # cardinality = nº of classes
label_model.fit(L_train=L_train, n_epochs=500, log_freq=100, seed=123)
label_model_acc = label_model.score(L=L_test, Y=Y_test, tie_break_policy="random")[
"accuracy"
]
print(f"{'Label Model Accuracy:':<25} {label_model_acc * 100:.1f}%")
return label_model
label_model = test_label_model(original_labelling_functions)
100%|██████████| 1586/1586 [00:14<00:00, 112.31it/s]
100%|██████████| 250/250 [00:02<00:00, 98.86it/s]
Label Model Accuracy: 85.6%
2. Extending and finding labeling functions with Rubrix¶
In this section, we’ll review some of the LFs from the original tutorial and see how to use Rubrix in combination with Snorkel.
Exploring the training set with Rubrix for initial inspiration¶
Rubrix lets you track data for different NLP tasks (such as Token Classification or Text Classification).
Let’s log our unlabelled training set into Rubrix for initial inspiration:
[7]:
records= []
for index, record in df_train.iterrows():
item = rb.TextClassificationRecord(
id=index,
inputs=record["text"],
metadata = {
"author": record.author,
"video": str(record.video)
}
)
records.append(item)
[8]:
rb.log(records=records, name="yt_spam_snorkel")
[8]:
BulkResponse(dataset='yt_spam_snorkel', processed=1586, failed=0)
After a few seconds, we have a fully searchable version of our unlabelled training set, which can be used for quickly defining new LFs or improve existing ones. We can of course view our data on a text editor, using Pandas or printing rows on a Jupyter Notebook, but Rubrix focuses on making this easy and powerful with features like searching using the Elasticsearch’s query string DSL, or the ability to log arbitrary inputs and metadata items.
First thing we can see on our Rubrix Dataset are the most frequent keywords on our text field. With just a quick look, we can see the coverage of two of the proposed keyword-based LFs (using the word “check” and “subscribe”):
Another thing we can do is to explore by metadata. Let’s say we want to check the distribution by authors, as maybe some authors are posting SPAM several times with different wordings. Here we can see one of the top posting authors, who’s also a top spammer, but seems to be using very similar messages:
Exploring some other top spammers, we see some of them use the word “money”, let’s check some examples using this keyword:

Yes, it seems using “money” has some correlation with SPAM and a overlaps with “check” but still covers other data points (as we can see in the Keywords component).
Let’s add this new LF to see its effect:
[22]:
@labeling_function()
def money(x):
return SPAM if "money" in x.text.lower() else ABSTAIN
[23]:
label_model = test_label_model(original_labelling_functions + [money])
100%|██████████| 1586/1586 [00:00<00:00, 3540.46it/s]
100%|██████████| 250/250 [00:00<00:00, 4887.67it/s]
Label Model Accuracy: 86.8%
Yes! With just some quick exploration we’ve improved the accuracy of the Label Model by 1.2%.
Exploring and improving heuristic LFs¶
We’ve already seen how to use keywords to label our data, the next step would be to use heuristics to do the labeling.
A simple approach proposed in the original Snorkel tutorial is checking the length of the comments’ text, considering it SPAM if its length is lower than a threshold.
To find a suitable threshold we can use Rubrix to visually explore the messages, similar to what we did before with the author selection.
[24]:
records= []
for index, record in df_train.iterrows():
item = rb.TextClassificationRecord(
id=index,
inputs=record["text"],
metadata = {
"textlen": str(len(record.text.split())), # Nº of 'words' in the sample
}
)
records.append(item)
[25]:
rb.log(records=records, name="yt_spam_snorkel_heuristic")
[25]:
BulkResponse(dataset='yt_spam_snorkel_heuristic', processed=1586, failed=0)
In the original tutorial, a threshold of 5 words is used, by exploring in Rubrix, we see we can go above that threshold. Let’s try with 20 words:
[26]:
@labeling_function()
def short_comment_2(x):
"""Ham comments are often short, such as 'cool video!'"""
return HAM if len(x.text.split()) < 20 else ABSTAIN
[27]:
# let's replace the original short comment function
original_labelling_functions[6]
[27]:
LabelingFunction short_comment, Preprocessors: []
[28]:
original_labelling_functions[6] = short_comment_2
[29]:
label_model = test_label_model(original_labelling_functions + [money])
100%|██████████| 1586/1586 [00:00<00:00, 5388.84it/s]
100%|██████████| 250/250 [00:00<00:00, 5542.86it/s]
Label Model Accuracy: 90.8%
Yes! With some additional exploration we’ve improved the accuracy of the Label Model by 5.2%.
[30]:
current_lfs = original_labelling_functions + [money]
Exploring third-party models LFs with Rubrix¶
Another class of Snorkel LFs are those third-party models, which can be combined with the Label Model.
Rubrix can be used for exploring how these models work with unlabelled data in order to define more precise LFs.
Let’s see this with the original Textblob’s based labelling functions.
Textblob¶
Let’s explore Textblob predictions on the training set with Rubrix:
[31]:
from textblob import TextBlob
records= []
for index, record in df_train.iterrows():
scores = TextBlob(record["text"])
item = rb.TextClassificationRecord(
id=str(index),
inputs=record["text"],
multi_label= False,
prediction=[("subjectivity", max(0.0, scores.sentiment.subjectivity))],
prediction_agent="TextBlob",
metadata = {
"author": record.author,
"video": str(record.video)
}
)
records.append(item)
[32]:
rb.log(records=records, name="yt_spam_snorkel_textblob")
[32]:
BulkResponse(dataset='yt_spam_snorkel_textblob', processed=1586, failed=0)
Checking the dataset, we can filter our data based on the prediction score of our classifier. This can help us since the predictions of our TextBlob tend to be SPAM the lower the subjectivity is. We can take advantage of this and filter the predictions by their score:
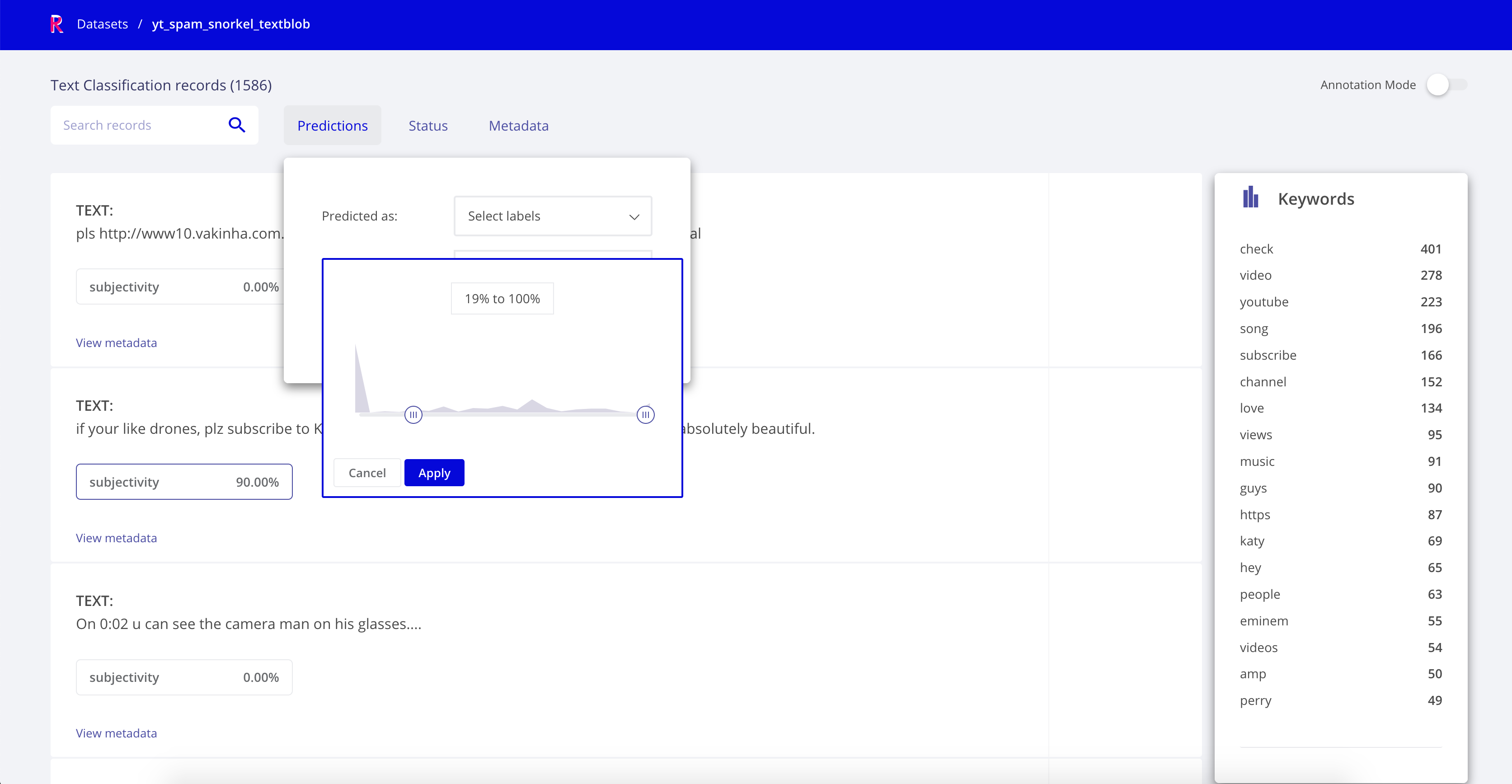
3. Checking and curating programatically created data¶
In this section, we’re going to analyse the training set we’re able to generate using our data programming model (the Label Model).
First thing, we need to do is to remove the unlabeled data. Remember we’re only labeling a subset using our model:
[ ]:
from snorkel.labeling import filter_unlabeled_dataframe
applier = PandasLFApplier(lfs=current_lfs)
L_train = applier.apply(df=df_train)
L_test = applier.apply(df=df_test)
df_train_filtered, probs_train_filtered = filter_unlabeled_dataframe(
X=df_train,
y=label_model.predict_proba(L_train), # Probabilities of each data point for each class
L=L_train
)
Now that we have our data, we can explore the results in Rubrix and manually relabel those cases that have been wrongly classified or keep exploring the performance of our LFs.
[38]:
records = []
for i, (index, record) in enumerate(df_train_filtered.iterrows()):
item = rb.TextClassificationRecord(
inputs=record["text"],
# our scores come from probs_train_filtered
# probs_train_filtered[i][j] is the probability the sample i belongs to class j
prediction=[("HAM", probs_train_filtered[i][0]), # 0 for HAM
("SPAM", probs_train_filtered[i][1])], # 1 for SPAM
prediction_agent="LabelModel",
)
records.append(item)
[40]:
rb.log(records=records, name="yt_filtered_classified_sample")
[40]:
BulkResponse(dataset='yt_filtered_classified_sample_2', processed=1568, failed=0)
With this Rubrix Dataset, we can explore the predictions of our label model. We could add the label model output as annotations to create a training set and share it subject matter experts for review e.g., for relabelling problematic data points.
To do this, simply adding the max. probability class as annotation:
[36]:
records = []
for i, (index, record) in enumerate(df_train_filtered.iterrows()):
gold_label = "SPAM" if probs_train_filtered[i][1] > probs_train_filtered[i][0] else "HAM"
item = rb.TextClassificationRecord(
inputs=record["text"],
# our scores come from probs_train_filtered
# probs_train_filtered[i][j] is the probability the sample i belongs to class j
prediction=[("HAM", probs_train_filtered[i][0]), # 0 for HAM
("SPAM", probs_train_filtered[i][1])], # 1 for SPAM
prediction_agent="LabelModel",
annotation=[gold_label]
)
records.append(item)
[37]:
rb.log(records=records, name="yt_filtered_classified_sample_with_annotation")
[37]:
BulkResponse(dataset='yt_filtered_classified_sample_with_annotation', processed=1568, failed=0)
Using the Annotation mode, you and other users could review the labels proposed by the Snorkel model and refine the training set, with a similar exploration pattern as we used for defining LFs.

4. Training and evaluating a classifier¶
The next thing we can do with our data is training a classifier using some of the most popular libraries such as Scikit-learn, Tensorflow or Pytorch. For simplicity, we will use scikit-learn, a widely-used library.
[41]:
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer(ngram_range=(1, 5)) # Bag Of Words (BoW) with n-grams
X_train = vectorizer.fit_transform(df_train_filtered.text.tolist())
X_test = vectorizer.transform(df_test.text.tolist())
Since we need to tell the model the class for each sample, and we have probabilities, we can assign to each sample the class with the highest probability.
[42]:
from snorkel.utils import probs_to_preds
preds_train_filtered = probs_to_preds(probs=probs_train_filtered)
And then build the classifier
[ ]:
from sklearn.linear_model import LogisticRegression
Y_test = df_test.label.values
sklearn_model = LogisticRegression(C=1e3, solver="liblinear")
sklearn_model.fit(X=X_train, y=preds_train_filtered)
[46]:
print(f"Test Accuracy: {sklearn_model.score(X=X_test, y=Y_test) * 100:.1f}%")
Test Accuracy: 91.6%
Let’s explore how our new model performs on the test data, in this case the annotation comes from the test set:
[47]:
records = []
for index, record in df_test.iterrows():
preds = sklearn_model.predict_proba(vectorizer.transform([record["text"]]))
preds = preds[0]
item = rb.TextClassificationRecord(
inputs=record["text"],
prediction=[("HAM", preds[0]), # 0 for HAM
("SPAM", preds[1])], # 1 for SPAM
prediction_agent="MyModel",
annotation=["SPAM" if record.label == 1 else "HAM"]
)
records.append(item)
[48]:
rb.log(records=records, name="yt_my_model_test")
[48]:
BulkResponse(dataset='yt_my_model_test', processed=250, failed=0)
This exploration is useful for error analysis and debugging, for example we can check all incorrectly classified examples using the Prediction filters.
Summary¶
In this tutorial, we have learnt to use Snorkel in combination with Rubrix for data programming workflows.