Rubrix documentation#
Rubrix is a production-ready framework for building and improving datasets for NLP projects.
Features#
Open: Rubrix is free, open-source, and 100% compatible with major NLP libraries (Hugging Face transformers, spaCy, Stanford Stanza, Flair, etc.). In fact, you can use and combine your preferred libraries without implementing any specific interface.
End-to-end: Most annotation tools treat data collection as a one-off activity at the beginning of each project. In real-world projects, data collection is a key activity of the iterative process of ML model development. Once a model goes into production, you want to monitor and analyze its predictions, and collect more data to improve your model over time. Rubrix is designed to close this gap, enabling you to iterate as much as you need.
User and Developer Experience: The key to sustainable NLP solutions is to make it easier for everyone to contribute to projects. Domain experts should feel comfortable interpreting and annotating data. Data scientists should feel free to experiment and iterate. Engineers should feel in control of data pipelines. Rubrix optimizes the experience for these core users to make your teams more productive.
Beyond hand-labeling: Classical hand labeling workflows are costly and inefficient, but having humans-in-the-loop is essential. Easily combine hand-labeling with active learning, bulk-labeling, zero-shot models, and weak-supervision in novel data annotation workflows.
Quickstart#
Getting started with Rubrix is easy, let’s see a quick example using the 🤗 transformers and datasets libraries:
pip install "rubrix[server]==0.18.0" "transformers[torch]" datasets
If you don’t have Elasticsearch (ES) running, make sure you have docker installed and run:
Note
Check the setup and installation section for further options and configurations regarding Elasticsearch.
docker run -d --name elasticsearch-for-rubrix -p 9200:9200 -p 9300:9300 -e "ES_JAVA_OPTS=-Xms512m -Xmx512m" -e "discovery.type=single-node" docker.elastic.co/elasticsearch/elasticsearch-oss:7.10.2
Then simply run:
python -m rubrix
Afterward, you should be able to access the web app at http://localhost:6900/.
The default username and password are rubrix and 1234.
🚒 If you have problems launching Rubrix, you can get direct support from the maintainers and other community member by joining Rubrix’s Slack Community
Now, let’s see an example: Bootstraping data annotation with a zero-shot classifier
Why:
The availability of pre-trained language models with zero-shot capabilities means you can, sometimes, accelerate your data annotation tasks by pre-annotating your corpus with a pre-trained zero-shot model.
The same workflow can be applied if there is a pre-trained “supervised” model that fits your categories but needs fine-tuning for your own use case. For example, fine-tuning a sentiment classifier for a very specific type of message.
Ingredients:
A zero-shot classifier from the 🤗 Hub:
typeform/distilbert-base-uncased-mnliA dataset containing news
A set of target categories:
Business,Sports, etc.
What are we going to do:
Make predictions and log them into a Rubrix dataset.
Use the Rubrix web app to explore, filter, and annotate some examples.
Load the annotated examples and create a training set, which you can then use to train a supervised classifier.
Use your favourite editor or a Jupyter notebook to run the following:
from transformers import pipeline
from datasets import load_dataset
import rubrix as rb
model = pipeline('zero-shot-classification', model="typeform/squeezebert-mnli")
dataset = load_dataset("ag_news", split='test[0:100]')
labels = ['World', 'Sports', 'Business', 'Sci/Tech']
records = []
for record in dataset:
prediction = model(record['text'], labels)
records.append(
rb.TextClassificationRecord(
text=record["text"],
prediction=list(zip(prediction['labels'], prediction['scores'])),
)
)
rb.log(records, name="news_zeroshot")
Now you can explore the records in the Rubrix UI at http://localhost:6900/.
The default username and password are rubrix and 1234.
Let’s filter the records predicted as Sports with high probability and use the bulk-labeling feature for labeling 5 records as Sports:
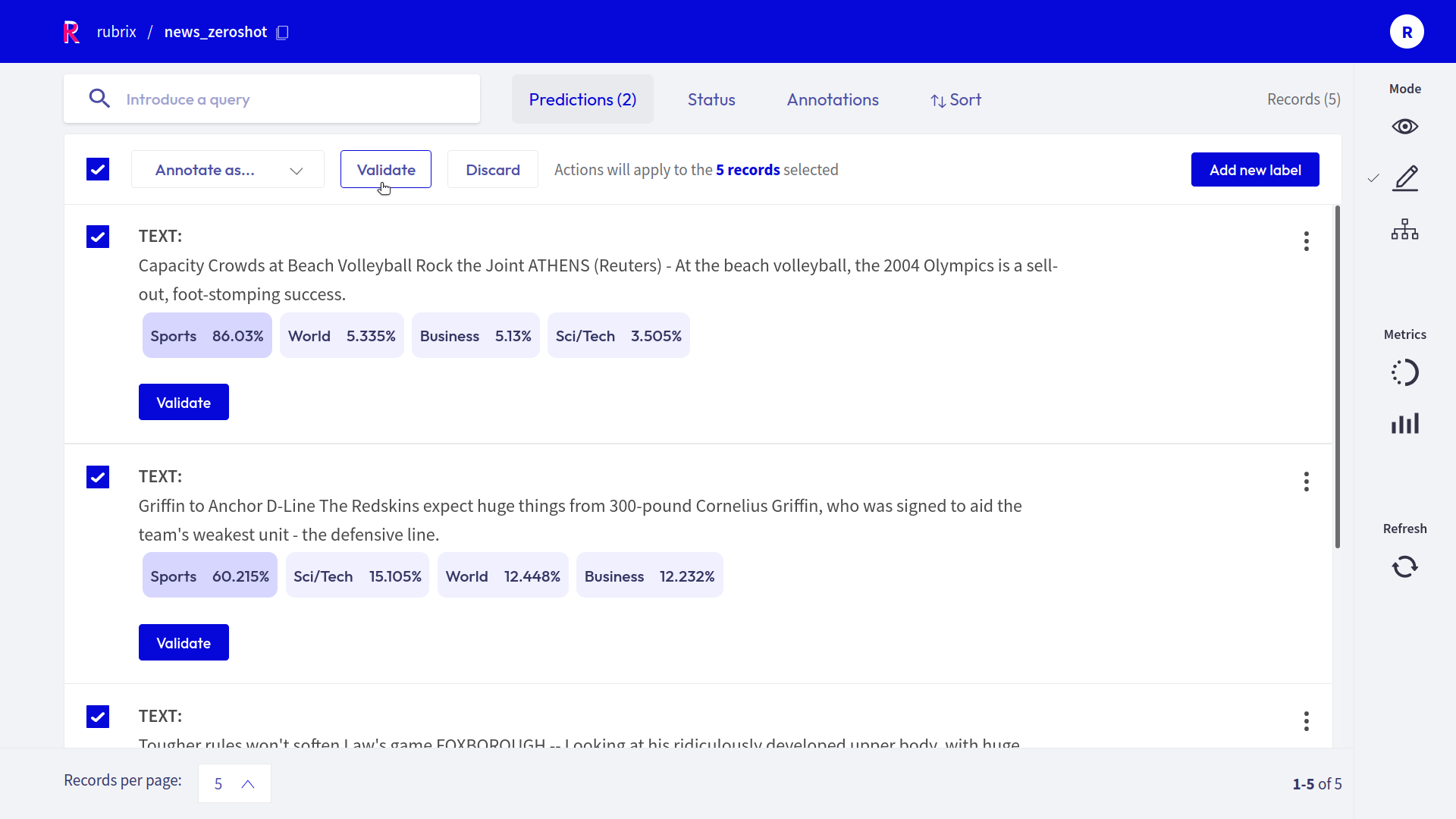
After a few iterations of data annotation, we can load the Rubrix dataset and create a training set to train or fine-tune a supervised model.
# load the Rubrix dataset and put it into a pandas DataFrame
rb_df = rb.load(name='news_zeroshot').to_pandas()
# filter annotated records
rb_df = rb_df[rb_df.status == "Validated"]
# select text input and the annotated label
train_df = pd.DataFrame({
"text": rb_df.text,
"label": rb_df.annotation,
})
Use cases#
Data labelling and review: collect labels to start a project from scratch or from existing live models.
Model monitoring and observability: log and observe predictions of live models.
Evaluation: easily compute “live” metrics from models in production, and slice evaluation datasets to test your system under specific conditions.
Model debugging: log predictions during the development process to visually spot issues.
Explainability: log token attributions to help you interpret model predictions.
Community#
You can join the conversation on Slack! We are a very friendly and inclusive community: