💫 Explore and analyze spaCy NER pipelines¶
In this tutorial, we will learn to log spaCy Name Entity Recognition (NER) predictions.
This is useful for:
🧐Evaluating pre-trained models.
🔎Spotting frequent errors both during development and production.
📈Improving your pipelines over time using Rubrix annotation mode.
🎮Monitoring your model predictions using Rubrix integration with Kibana
Let’s get started!
Introduction¶
In this tutorial we will learn how to explore and analyze spaCy NER pipelines in an easy way.
We will load the Gutenberg Time dataset from the Hugging Face Hub and use a transformer-based spaCy model for detecting entities in this dataset and log the detected entities into a Rubrix dataset. This dataset can be used for exploring the quality of predictions and for creating a new training set, by correcting, adding and validating entities.
Then, we will use a smaller spaCy model for detecting entities and log the detected entities into the same Rubrix dataset for comparing its predictions with the previous model. And, as a bonus, we will use Rubrix and spaCy on a more challenging dataset: IMDB.
Setup¶
Rubrix is a free and open-source tool to explore, annotate, and monitor data for NLP projects.
If you are new to Rubrix, visit and ⭐ star Rubrix for more materials like and detailed docs: Github repo
If you have not installed and launched Rubrix yet, check the Setup and Installation guide.
For this tutorial we also need the third party libraries datasets and of course spaCy together with pytorch, which can be installed via git:
[ ]:
%pip install torch -qqq
%pip install datasets "spacy[transformers]~=3.0" protobuf -qqq
Note
If you want to skip running the spaCy pipelines, you can also load the resulting Rubrix records directly from the Hugging Face Hub, and continue the tutorial logging them to the Rubrix web app. For example:
import rubrix as rb
from datasets import load_dataset
records = rb.read_datasets(
load_dataset("rubrix/gutenberg_spacy_ner", split="train"),
task="TokenClassification",
)
The Rubrix records of this tutorial are available under the names “rubrix/gutenberg_spacy_ner” and “rubrix/imdb_spacy_ner”.
Our dataset¶
For this tutorial, we’re going to use the Gutenberg Time dataset from the Hugging Face Hub. It contains all explicit time references in a dataset of 52,183 novels whose full text is available via Project Gutenberg. From extracts of novels, we are surely going to find some NER entities.
[ ]:
from datasets import load_dataset
dataset = load_dataset("gutenberg_time", split="train", streaming=True)
Let’s have a look at the first 5 examples of the train set.
[2]:
import pandas as pd
pd.DataFrame(dataset.take(5))
[2]:
| guten_id | hour_reference | time_phrase | is_ambiguous | time_pos_start | time_pos_end | tok_context | |
|---|---|---|---|---|---|---|---|
| 0 | 4447 | 5 | five o'clock | True | 145 | 147 | I crossed the ground she had traversed , notin... |
| 1 | 4447 | 12 | the fall of the winter noon | True | 68 | 74 | So profoundly penetrated with thoughtfulness w... |
| 2 | 28999 | 12 | midday | True | 46 | 47 | And here is Hendon , and it is time for us to ... |
| 3 | 28999 | 12 | midday | True | 133 | 134 | Sorrows and trials she had had in plenty in he... |
| 4 | 28999 | 0 | midnight | True | 43 | 44 | Jeannie joined her friend in the window-seat .... |
Logging spaCy NER entities into Rubrix¶
Using a Transformer-based pipeline¶
Let’s download our Roberta-based pretrained pipeline and instantiate a spaCy nlp pipeline with it.
[ ]:
!python -m spacy download en_core_web_trf
[ ]:
import spacy
nlp = spacy.load("en_core_web_trf")
Now let’s apply the nlp pipeline to the first 50 examples in our dataset, collecting the tokens and NER entities.
[ ]:
import rubrix as rb
from tqdm.auto import tqdm
# Creating an empty record list to save all the records
records = []
# Iterate over the first 50 examples of the Gutenberg dataset
for record in tqdm(list(dataset.take(50))):
# We only need the text of each instance
text = record["tok_context"]
# spaCy Doc creation
doc = nlp(text)
# Entity annotations
entities = [
(ent.label_, ent.start_char, ent.end_char)
for ent in doc.ents
]
# Pre-tokenized input text
tokens = [token.text for token in doc]
# Rubrix TokenClassificationRecord list
records.append(
rb.TokenClassificationRecord(
text=text,
tokens=tokens,
prediction=entities,
prediction_agent="en_core_web_trf",
)
)
[ ]:
rb.log(records=records, name="gutenberg_spacy_ner")
If you go to the gutenberg_spacy_ner dataset in Rubrix you can explore the predictions of this model.
You can:
Filter records containing specific entity types,
See the most frequent “mentions” or surface forms for each entity. Mentions are the string values of specific entity types, such as for example “1 month” can be the mention of a duration entity. This is useful for error analysis, to quickly see potential issues and problematic entity types,
Use the free-text search to find records containing specific words,
And validate, include or reject specific entity annotations to build a new training set.
Using a smaller but more efficient pipeline¶
Now let’s compare with a smaller, but more efficient pre-trained model.
Let’s first download it:
[ ]:
!python -m spacy download en_core_web_sm
[ ]:
import spacy
nlp = spacy.load("en_core_web_sm")
[ ]:
# Creating an empty record list to save all the records
records = []
# Iterate over the first 50 examples of the Gutenberg dataset
for record in tqdm(list(dataset.take(50))):
# We only need the text of each instance
text = record["tok_context"]
# spaCy Doc creation
doc = nlp(text)
# Entity annotations
entities = [
(ent.label_, ent.start_char, ent.end_char)
for ent in doc.ents
]
# Pre-tokenized input text
tokens = [token.text for token in doc]
# Rubrix TokenClassificationRecord list
records.append(
rb.TokenClassificationRecord(
text=text,
tokens=tokens,
prediction=entities,
prediction_agent="en_core_web_sm",
)
)
[ ]:
rb.log(records=records, name="gutenberg_spacy_ner")
Exploring and comparing en_core_web_sm and en_core_web_trf models¶
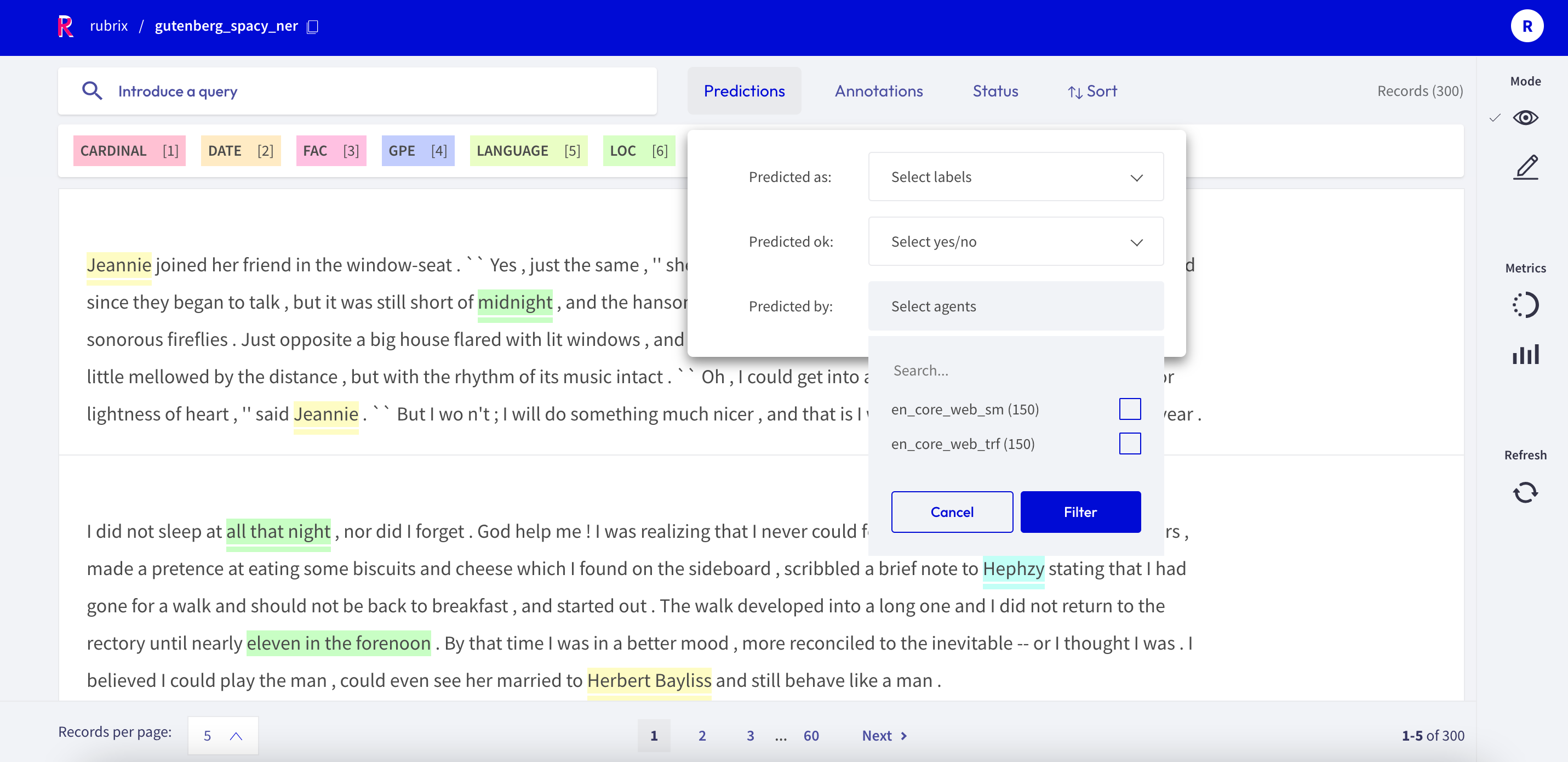
If you go to your gutenberg_spacy_ner dataset, you can explore and compare the results of both models.
To only see predictions of a specific model, you can use the predicted by filter, which comes from the prediction_agent parameter of your TextClassificationRecord.
Explore the IMDB dataset¶
So far, both spaCy pretrained models seem to work pretty well. Let’s try with a more challenging dataset, which is more dissimilar to the original training data these models have been trained on.
[ ]:
imdb = load_dataset("imdb", split="test")
[ ]:
records = []
for record in tqdm(imdb.select(range(50))):
# We only need the text of each instance
text = record["text"]
# spaCy Doc creation
doc = nlp(text)
# Entity annotations
entities = [
(ent.label_, ent.start_char, ent.end_char)
for ent in doc.ents
]
# Pre-tokenized input text
tokens = [token.text for token in doc]
# Rubrix TokenClassificationRecord list
records.append(
rb.TokenClassificationRecord(
text=text,
tokens=tokens,
prediction=entities,
prediction_agent="en_core_web_sm",
)
)
[ ]:
rb.log(records=records, name="imdb_spacy_ner")
Exploring this dataset highlights the need of fine-tuning for specific domains.
For example, if we check the most frequent mentions for Person, we find two highly frequent missclassified entities: gore (the film genre) and Oscar (the prize).
You can easily check every example by using the filters and search-box.
Summary¶
In this tutorial, you learned how to log and explore differnt spaCy NER models with Rubrix. Now you can:
Build custom dashboards using Kibana to monitor and visualize spaCy models.
Build training sets using pre-trained spaCy models.
Next steps¶
📚 Rubrix documentation for more guides and tutorials.¶
🙋♀️ Join the Rubrix community! A good place to start is the discussion forum.¶
⭐ Rubrix Github repo to stay updated.¶
Appendix: Log datasets to the Hugging Face Hub¶
Here we will show you an example of how you can push a Rubrix dataset (records) to the Hugging Face Hub. In this way you can effectively version any of your Rubrix datasets.
[ ]:
records = rb.load("gutenberg_spacy_ner", as_pandas=False)
records.to_datasets().push_to_hub("<name of the dataset on the HF Hub>")