✨ Using Rubrix with spaCy¶
This tutorial will walk you through the process of using spaCy with Rubrix to track and monitor Name Entity Recognition (NER) predictions.
Introduction¶
In this tutorial we will:
Load the Gutenberg Time dataset from the Hugging Face Hub.
Use a transformer-based spaCy model for detecting entities in this dataset and log the detected entities into a Rubrix dataset. This dataset can be used for exploring the quality of predictions and for creating a new training set, by correcting, adding and validating entities.
Use a smaller spaCy model for detecting entities and log the detected entities into the same Rubrix dataset for comparing its predictions with the previous model.
Install tutorial dependencies¶
In this tutorial, we’ll use the datasets and spaCy libraries and the en_core_web_trf pretrained English model, a Roberta-based spaCy model . If you do not have them installed, run:
[ ]:
%pip install datasets -qqq
%pip install -U spacy -qqq
%pip install protobuf
Setup Rubrix¶
If you have not installed and launched Rubrix, check the installation guide.
[ ]:
import rubrix as rb
Our dataset¶
For this tutorial, we’re going to use the Gutenberg Time dataset from the Hugging Face Hub. It contains all explicit time references in a dataset of 52,183 novels whose full text is available via Project Gutenberg. From extracts of novels, we are surely going to find some NER entities.
[ ]:
from datasets import load_dataset
dataset = load_dataset("gutenberg_time", split="train[0:20]")
Let’s take a look at our dataset! Starting by the length of it and an sneak peek to one instance.
[ ]:
dataset[1]
[ ]:
dataset
Logging spaCy NER entities into Rubrix¶
Using a Transformer-based pipeline¶
Let’s install and load our roberta-based pretrained pipeline and apply it to one of our dataset records:
[ ]:
!python -m spacy download en_core_web_trf
[8]:
import spacy
nlp = spacy.load("en_core_web_trf")
doc = nlp(dataset[0]["tok_context"])
doc
[8]:
I crossed the ground she had traversed , noting every feature surrounding it , the curving wheel-track , the thin prickly sand-herbage , the wave - mounds , the sparse wet shells and pebbles , the gleaming flatness of the water , and the vast horizon-boundary of pale flat land level with shore , looking like a dead sister of the sea . By a careful examination of my watch and the sun 's altitude , I was able to calculate what would , in all likelihood , have been his height above yonder waves when her chair was turned toward the city , at a point I reached in the track . But of the matter then simultaneously occupying my mind , to recover which was the second supreme task I proposed to myself-of what . I also was thinking upon the stroke of five o'clock , I could recollect nothing . I could not even recollect whether I happened to be looking on sun and waves when she must have had them full and glorious in her face . With the heartiest consent I could give , and a blank cheque , my father returned to England to hire forthwith a commodious yacht , fitted and manned . Before going he discoursed of prudence in our expenditure ; though not for the sake of the mere money in hand , which was a trifle , barely more than the half of my future income ; but that the squire , should he by and by bethink him of inspecting our affairs , might perceive we were not spendthrifts .
Now let’s apply the nlp pipeline to our dataset records, collecting the tokens and NER entities.
[11]:
records = []
for record in dataset:
# We only need the text of each instance
text = record["tok_context"]
# spaCy Doc creation
doc = nlp(text)
# Entity annotations
entities = [
(ent.label_, ent.start_char, ent.end_char)
for ent in doc.ents
]
# Pre-tokenized input text
tokens = [token.text for token in doc]
# Rubrix TokenClassificationRecord list
records.append(
rb.TokenClassificationRecord(
text=text,
tokens=tokens,
prediction=entities,
prediction_agent="spacy.en_core_web_trf",
)
)
[12]:
rb.log(records=records, name="gutenberg_spacy_ner")
[12]:
BulkResponse(dataset='gutenberg_spacy_ner', processed=20, failed=0)
If you go to the gutenberg_spacy_ner dataset in Rubrix you can explore the predictions of this model:
You can filter records containing specific entity types.
You can see the most frecuent “mentions” or surface forms for each entity. Mentions are the string values of specific entity types, such as for example “1 month” can be the mention of a duration entity. This is useful for error analysis, to quickly see potential issues and problematic entity types.
You can use the free-text search to find records containing specific words.
You could validate, include or reject specific entity annotations to build a new traning set.

Using a smaller but more efficient pipeline¶
Now let’s compare with a smaller, but more efficient pre-trained model. Let’s first download it
[ ]:
!python -m spacy download en_core_web_sm
[ ]:
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp(dataset[0]["tok_context"])
[16]:
records = [] # Creating and empty record list to save all the records
for record in dataset:
text = record["tok_context"] # We only need the text of each instance
doc = nlp(text) # spaCy Doc creation
# Entity annotations
entities = [
(ent.label_, ent.start_char, ent.end_char)
for ent in doc.ents
]
# Pre-tokenized input text
tokens = [token.text for token in doc]
# Rubrix TokenClassificationRecord list
records.append(
rb.TokenClassificationRecord(
text=text,
tokens=tokens,
prediction=entities,
prediction_agent="spacy.en_core_web_sm",
)
)
[17]:
rb.log(records=records, name="gutenberg_spacy_ner")
[17]:
BulkResponse(dataset='gutenberg_spacy_ner', processed=20, failed=0)
Exploring and comparing en_core_web_sm and en_core_web_trf models¶
If you go to your gutenberg_spacy_ner you can explore and compare the results of both models.
A handy feature is the predicted by filter, which comes from the prediction_agent parameter of your TextClassificationRecord.
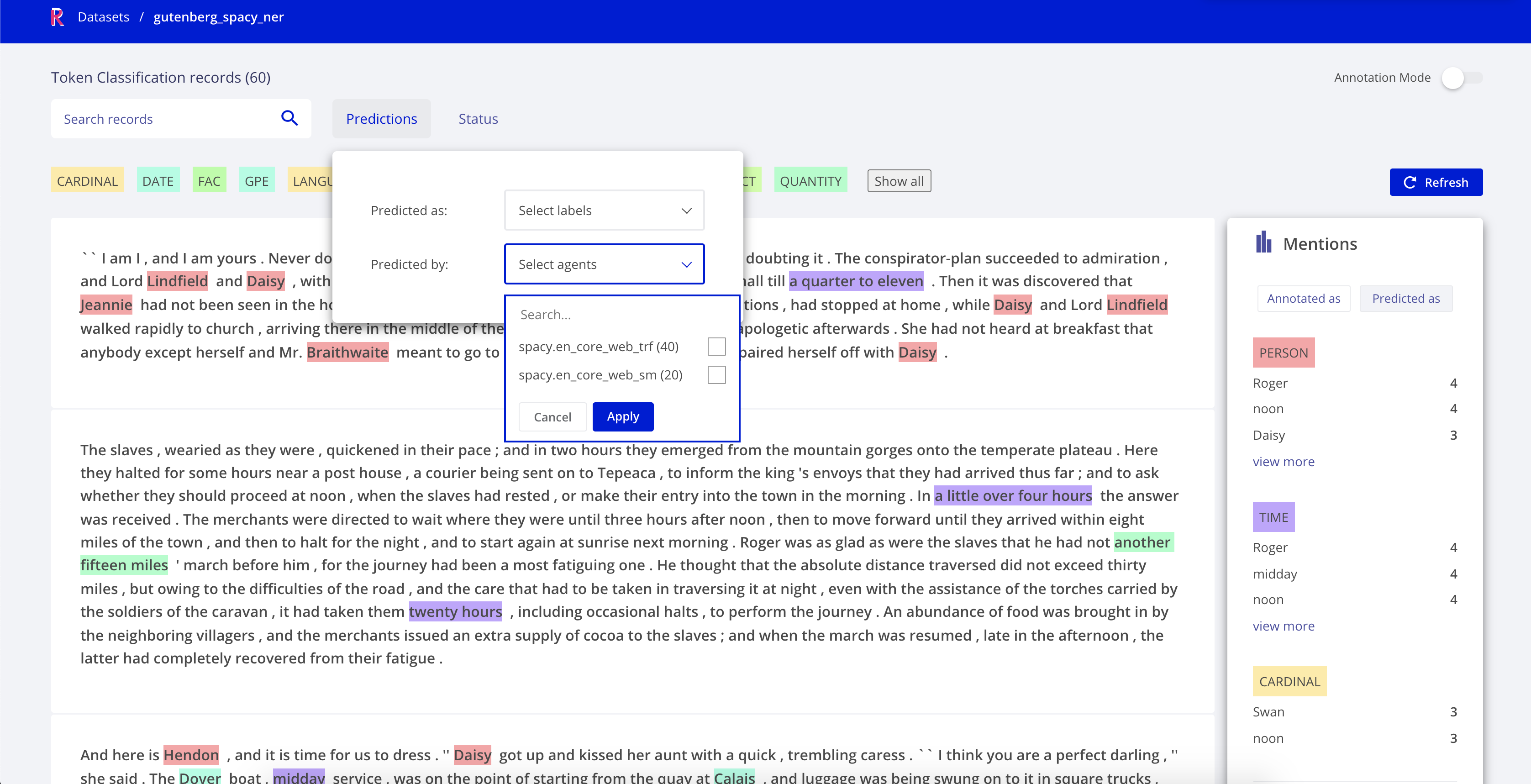
Some quick qualitative findings about these two models applied to this sample:
en_core_web_trfmakes more conservative predictions, most of them accurate but misses a number of entities (higher precision, less recall for entities likeCARDINAL).en_core_web_smhas less precision for most of the entities, confusing for examplePERSONwithORGentities, even with the same surface form within the same paragraph, but has better recall for entities likeCARDINAL.For
TIMEentities both model show almost the same distribution and are quite accurate. This could be further analysed by logging the timeannotationsin the dataset.
Summary¶
In this tutorial, we have learnt to log and explore differnt spaCy NER models with Rubrix. Using what we´ve learnt here you can:
Build custom dashboards using Kibana to monitor and visualize spaCy models.
Build training sets using pre-trained spaCy models.