✨ Using Rubrix with spaCy¶
In this tutorial, we will walk through the process of using Rubrix with spaCy, one of the most-widely used NLP libraries.
Introduction¶
Our goal is to show you how to explore ``spaCy`` NER predictions with Rubrix.
Install tutorial dependencies¶
In this tutorial we will be using datasets and spaCy libraries and the en_core_web_trf pretrained English model, a Roberta-based spaCy model . If you do not have them installed, run:
[ ]:
%pip install datasets -qqq
%pip install -U spacy -qqq
%pip install protobuf
Setup Rubrix¶
If you have not installed and launched Rubrix, check the installation guide.
[ ]:
import rubrix as rb
Our dataset¶
For this tutorial, we are going to use the Gutenberg Time dataset from the Hugging Face Hub. It contains all explicit time references in a dataset of 52,183 novels whose full text is available via Project Gutenberg. From extracts of novels, we are surely going to find some NER entities. Well, technically, spaCy is going to find them.
[ ]:
from datasets import load_dataset
dataset = load_dataset("gutenberg_time", split="train[0:20]")
Let’s take a look at our dataset! Starting by the length of it and an sneak peek to one instance.
[ ]:
dataset[1]
[ ]:
dataset
Logging spaCy NER entities into Rubrix¶
Using a Transformer-based pipeline¶
Let’s install and load our roberta-based pretrained pipeline and apply it to one of our dataset records:
[ ]:
!python -m spacy download en_core_web_trf
[ ]:
import spacy
nlp = spacy.load("en_core_web_trf")
doc = nlp(dataset[0]["tok_context"])
doc
Now let’s apply the nlp pipeline to our dataset records, collecting the tokens and NER entities.
[ ]:
records = [] # Creating and empty record list to save all the records
for record in dataset:
text = record["tok_context"] # We only need the text of each instance
doc = nlp(text) # spaCy Doc creation
# Entity annotations
entities = [
(ent.label_, ent.start_char, ent.end_char)
for ent in doc.ents
]
# Pre-tokenized input text
tokens = [token.text for token in doc]
# Rubrix TokenClassificationRecord list
records.append(
rb.TokenClassificationRecord(
text=text,
tokens=tokens,
prediction=entities,
prediction_agent="spacy.en_core_web_trf",
)
)
[ ]:
rb.log(records=records, name="gutenberg_spacy_ner")
Using a smaller but more efficient pipeline¶
Now let’s compare with a smaller, but more efficient pre-trained model. Let’s first download it
[ ]:
!python -m spacy download en_core_web_sm -qqq
[ ]:
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp(dataset[0]["tok_context"])
doc
[ ]:
records = [] # Creating and empty record list to save all the records
for record in dataset:
text = record["tok_context"] # We only need the text of each instance
doc = nlp(text) # spaCy Doc creation
# Entity annotations
entities = [
(ent.label_, ent.start_char, ent.end_char)
for ent in doc.ents
]
# Pre-tokenized input text
tokens = [token.text for token in doc]
# Rubrix TokenClassificationRecord list
records.append(
rb.TokenClassificationRecord(
text=text,
tokens=tokens,
prediction=entities,
prediction_agent="spacy.en_core_web_sm",
)
)
[ ]:
rb.log(records=records, name="gutenberg_spacy_ner")
Exploring and comparing en_core_web_sm and en_core_web_trf models¶
If you go to your gutenberg_spacy_ner you can explore and compare the results of both models.
A handy feature is the predicted by filter, which comes from the prediction_agent parameter of your TextClassificationRecord.
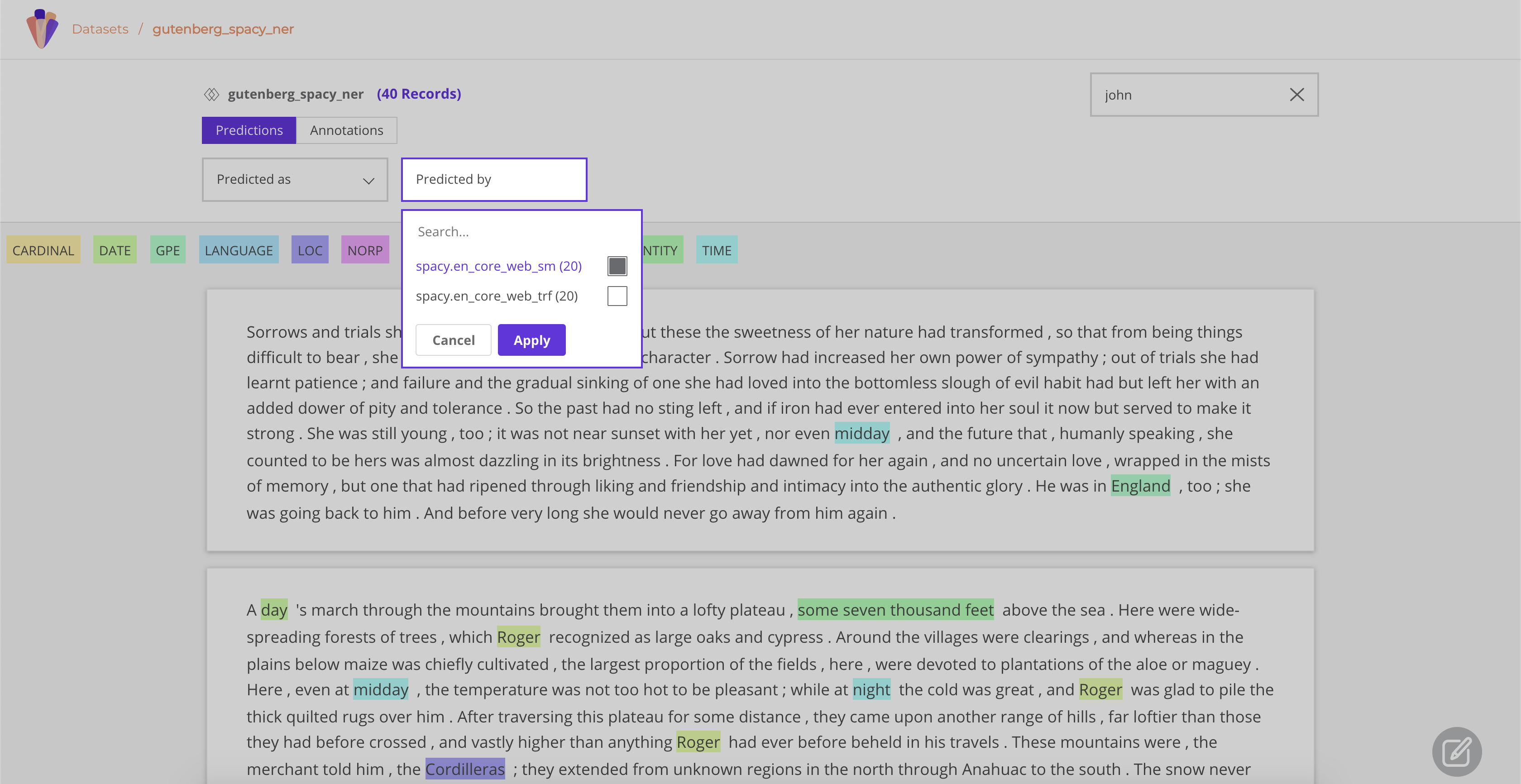
Some quick qualitative findings about these two models applied to this sample:
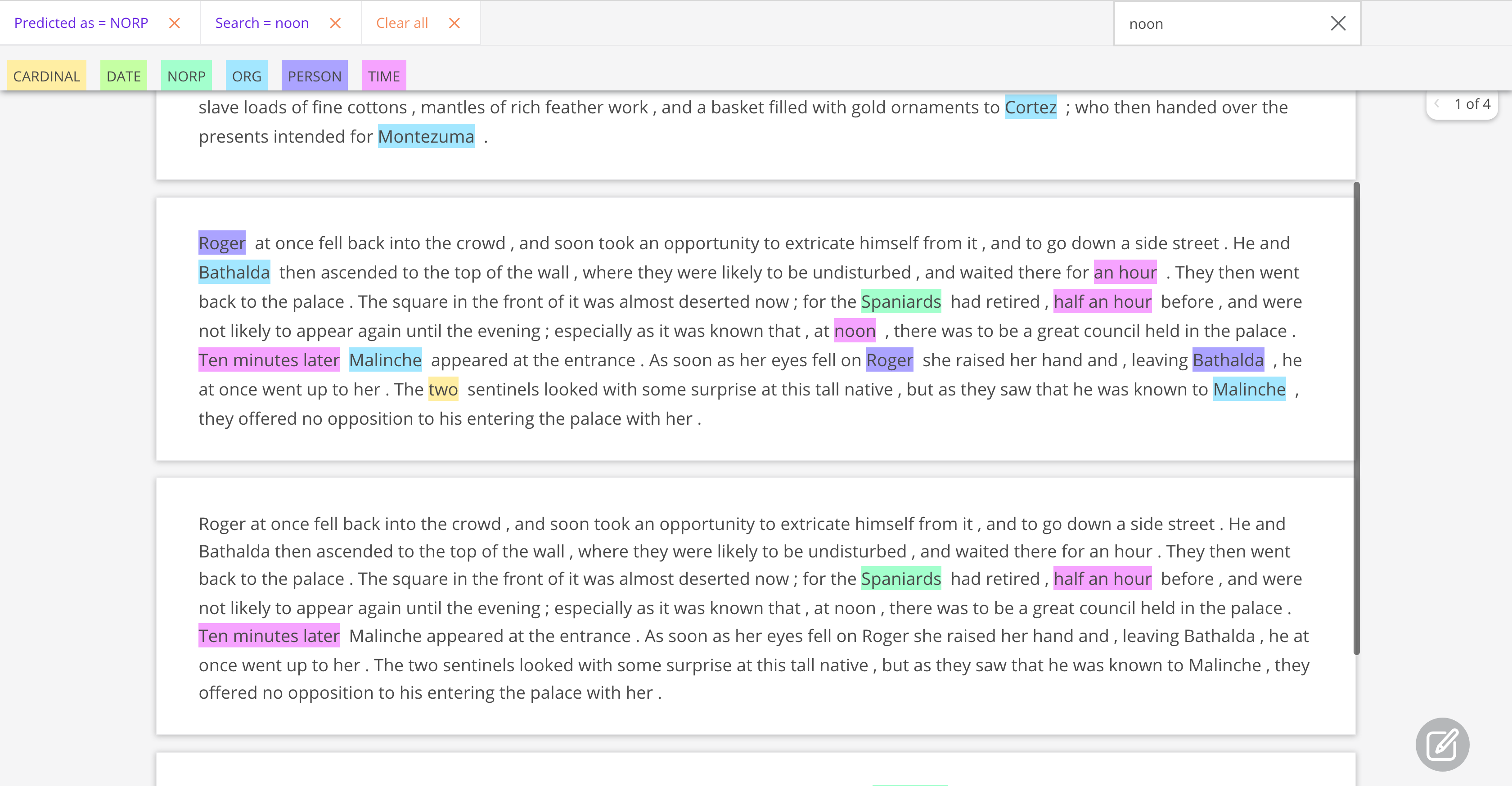
en_core_web_trfmakes more conservative predictions, most of them accurate but misses a number of entities (higher precision, less recall for entities likeCARDINAL).en_core_web_smhas less precision for most of the entities, confusing for examplePERSONwithORGentities, even with the same surface form within the same paragraph, but has better recall for entities likeCARDINAL.For
TIMEentities both model show almost the same distribution and are quite accurate. This could be further analysed by logging the timeannotationsin the dataset.
As an illustration of these findings, see an example of a records with en_core_web_sm (top) and en_core_web_trf (bottom) predicted entities.
Summary¶
In this tutorial, we have learnt to log and explore spaCy NER models with Rubrix.
Next steps¶
We invite you to check our other tutorials and join our community, a good place to start is our discussion forum.